(A Deep Dive on Balancing Risks, Costs, and Rewards for Product Managers)
In my last long post, I wrote a lot about unblocking work, fixing prioritization problems, and getting things done. But I didn’t address the question how to figure out what work is worth doing, what should be on your roadmap, and how these things should make it onto the roadmap.
Figuring out what to work on is about unpacking what the heck ROI is, how to figure it out, and how to actually get a ‘return on investment’. That’s the work product management should be doing, but it’s also broadly applicable to anyone who needs to make effective roadmaps and business decisions... regardless of role or department.
At the end of the day, choosing what to work on is one of the most important things a leader should do. And that decision is all about the balance between three things: costs, risks, and rewards.
Table of Contents
- 1. Introduction: Strong roadmaps are about opportunities, not solutions
- 2. What Business Decisions Are
- 3. Understanding Rewards
- 4. Understanding Risks
- 5. Understanding Costs
- 6. Putting it all together: Speed, Cycles, and Safeguards
This is a long post... it's roughly 11,300 words! To make it easier to read/annotate, I've also turned it into an epub ebook and PDF. If you prefer to read it that way (or you found this helpful and want to leave a "tip"), you can buy the ebook version for $1.99. This helps offset the cost of writing and editing. Thank you!
1. Introduction: Strong roadmaps are about opportunities, not solutions
A roadmap is a deeply political thing.
A roadmap represents the hopes and dreams of a company, what it expects the future to look like, how it plans on getting there, and what risks it is willing to take.
Because of this, roadmaps inspire debate from every corner of the company. Product and engineering teams, investors, marketers, customer success, sales teams, and every IC, manager, director, and executive has a perspective on what to do and why.
Good roadmaps find ways to strike a balance. They do this by focusing not on solutions, features or tactics, but on opportunities and problems to solve.
This might sound a little counterintuitive at first. Most public-facing “roadmaps” are actually upcoming feature lists, such as “added support for Bluetooth” or “ability to edit content”. Those are fine when you’re telegraphing to the general public what they should be expecting in the near future. In fact, that’s a great launch strategy. But it’s not a great business roadmap.
Consider the following examples of roadmap items for a hypothetical chat app:
- A: “We need to build an integration to WhatsApp”
- B: “We need to launch a WhatsApp integration to Increase engagement and chat volume in Latin American markets.”
- C: “We need to increase engagement and chat volume in Latin America and deflect emerging competition for our market share. If we create 10-25% more chat volume for customers or reach feature parity with competitors within the next 3 months (when contracts renew), then we won’t lose existing customers and will gain $X new revenue through renewed contracts. We’ll start by launching a WhatsApp integration targeting customers underserved through other channels (15 million people in the current market).”
What’s the difference between these?
In the A example, you have a task removed from any context. Why are you building that thing? How do you know if it made any difference at all? Has it solved any problem? Do you even know what problem you’re solving?
In the B example, you begin to have context. You now know the goals and target market. You’re still building the same thing, but now you know how it fits into the bigger picture. You also have some more idea about what the feature needs to do — for example, it needs Spanish-language support, and to be successful it needs to increase certain metrics.
In the C example, you skip the task entirely in favor of focusing on the business problem, with specificity. You’re no longer guessing at what success looks like. You begin to understand that the problem is complex and there are a few different options for solving it. You have a relevant timeline. All of this begins to inform a tactical plan for what you can do: you’ll start with a WhatsApp integration because it’s a quick win and easy to launch, then add in additional features based on interviews with the customers you service.
Most people end up confusing tactical plans and to-do lists with business opportunities. This leads to a focus on building things rather than solving problems (what Melissa Perri calls “the build trap”). If you flip that and focus instead on opportunities, you gain flexibility and impact. You also gain the ability to draw a clear line between costs, risk, and rewards of pursuing any opportunity.
Moreover, costs, risk, and rewards are not nebulous, hand-wavey concepts that you can guesstimate through. They’re _specific_ factors that you can play with to find the best balance and thus the best business case for why you should work on one thing rather than another.
The other interesting thing that happens is that what you build ends up mattering less than the process of how it gets on the roadmap:
- A good roadmap is about problems and opportunities, not about solutions.
- Because any problem can be solved in many different ways, this gives you flexibility to try out different solutions instead of fighting over or getting stuck any single idea.
- Every opportunity is a balancing act between costs, potential rewards, and the risks/probabilities encountered along the way.
- Teams that are are able to go through the process of identifying and testing opportunities quickly tend to get to quantifiably better ideas and execute those ideas quicker. They are able to keep costs low by abandoning things that aren’t working, keep risks in check by creating effective feedback mechanisms, and keep the rewards coming by focusing on the goals and intents rather than specific tasks.
- So what you end up choosing to do matters less than having a system for moving through a loop of testing different opportunities and having the right feedback mechanisms to adjust your execution.
Why write this and who is it for?
This is for Product Managers who are doing the wrong jobs
Across companies, I’ve found too many product managers that are focused on doing the wrong job. There’s an awful anti-pattern of people calling product managers the “mini-CEOs” and having them end up acting as tiny dictators: build this, build that. You end up with legions of product managers pretending to be designers and software engineers, busy writing requirements for what the product should and should not do, how it should and should not look and feel.
When product managers become feature dictators, everyone loses. Designers become pixel pushers, engineers turn into typists, and marketing and sales folks feel like they’re walled off from the “technology” side of the house. And product managers end up bringing nothing unique to the table, just mimicry of the work of other departments.
If you flip that and have product management focus on opportunity validation, you give autonomy for designers to flex their understanding of human interactions and service design, and for engineers to give proper guidance (and forward planning) on what to build and how to build it, including what’s simple, what’s complicated, and how to best create something given the rest of the software architecture. It also brings the important customer-facing voices of sales, marketing, and customer service into the conversation and makes them partners in the success or failure of every effort.
This is also because most advice online is incomplete
The other challenge is that there exists a huge body of advice around everything I’m writing about, but most of that advice is piecemeal, incomplete, or contextless. That means that most of the advice is hard to practice (or won’t get you the results you want).
Without the proper context, you’re more likely get a mismatch between a problem and what you’re implementing. Advice mismatch end up sounding like “this is what we did at my last company” or “I tried that earlier and it didn’t work as promised” or “but this best practice has been recommended by [insert company name] and they really know what they’re talking about”.
My experience has been that figuring out the right problem is 90% of the work. When you identify and define the problem correctly, the solution often becomes obvious.
So this guide — I’m not sure what else to call it — is designed to systematically approach the problem of navigating costs-risks-rewards when figuring out what to work on.
By teasing those things apart, it’s easy to see how different risks require different risk-management strategies, how costs run up and how to keep them down, how to create feedback loops to identify if you’re moving in the right direction, and how to figure out what is a real reward and what is reward-like but not actually impactful.
Along the way, I’m also going to highlight some stories and tactics that have worked for me to solve those problems. I’ll also try to illustrate it with examples (and failures) from the roadmaps I’ve had to put together or worked on or had been handed down to me.
Let’s get started.
2. What Business Decisions Are
Every business decision is a balance between:
- Risks (probability that things will/won’t go right),
- Costs (time, money, and effort), and
- Rewards (the possible outcomes of things going right).
A roadmap is a commitment to a set of business decisions.
Making better decisions is about finding ways to play with those three levers and about what you can do to skew those options, and what to do when you can’t.
Skewing the options means being creative with your constraints and asking yourself:
- How can I decrease the risks associated with my projects to make them more likely to succeed?
- How can I lower the costs to build so that I have more opportunities to keep trying (“shots at goal”)?
- How can I choose problems where the potential rewards justify the work?
This might sound familiar to some folks: risks, costs, and rewards are really just another way of saying “ROI” or return on investment. But ROI has a popular usage and history and I don’t think its useful to try to co-opt that and create inevitable confusions. But at the end of the day, it’s still about what you need to invest (costs), what your return is expected to be (rewards), and what you need to get from point A to point B (risks).
3. Understanding Rewards
“The purpose of business is to create and keep a customer. " he argued. And: "What does our customer find valuable?" is the most important question companies can ask themselves.”
- The Wisdom of Peter Drucker, from A to Z
If I skip to the punchline for a minute, the reason for existence of any business is to make money. I’m not trying to be calloused or jaded. Businesses are a form of law-described organizations designed to facilitate groups of people working together to generate trade and commerce.
Businesses make money by creating, refining, or arbitraging something of value, something a customer — or a large enough volume of customers — is willing to pay for. Businesses survive and thrive when the amount of money they make exceeds whatever their costs to produce and deliver the products/services are.
(So if you’re interested in running a successful business, these are your two crazy tips: do something people are willing to pay for, and generate more money than you spend.)
It’s important to understand this context — and more specifically, how your business makes money and what your customers find valuable enough to pay for — to figure out how to chase the right rewards.
The first “roadmap” I worked with was a list of tasks and projects to complete. When that list was completed, management added more projects to the list, mostly to make sure we had work to do.
Much later, the first “real” roadmap I worked with was something that was handed down to me. It was a well-meaning spreadsheet with 40 different parameters evaluating all of the projects we had on our plate, plus things different teams wanted to work on in the future. There was another column that calculated expected value based on weighing certain fields. It was all pretty subjective, and it was still just a project list at the end of the day.
To use the “cart before the horse” metaphor, starting with projects and features is like trying to build a cart before you know where you’re going. Maybe you don’t need a cart to get there. Maybe a horse is good enough. Maybe you need a sled and pack of huskies. Maybe you need a boat. So where are you going and why?
But, I inherited that roadmap and it was as good a starting point as any. After a lot of discussion and weigh-in from different department heads, we ended up narrowing down 40 different parameters to eight fields, then five, and eventually three fields that really mattered.
These three reasons (which I ended up calling “Rewards” for reasons that will become clear later) have been applicable across every business I’ve worked at since. They are:
- Reward 1: Expand existing business (increase existing revenue)
- Reward 2: Enter new markets (create new opportunities/new business lines)
- Reward 3: Increase profit margins (Increase profit margins/decrease costs while keeping revenue stable)
Everything ultimately ties back to these rewards/reasons. They’re the intent of the work — the “why” of what you’re doing.
By starting with the opportunity rather than with a solution, you can be nimble with figuring out what to do to reach that intent. This allows you to focus on outcomes rather than getting locked into specific tasks that might no longer be relevant if circumstances change.
However, this is easier said than done. Most people think in solutions-oriented ways. They skip over defining the opportunity and get straight to a proposal. If you let them, they’ll follow up with two or three more proposals. When someone comes to you with a brilliant idea that you should work on, it often takes a couple of questions to get to why they think the idea is so brilliant and what problem it solves (if any... too many companies today seem to be solutions in search of a problem). Only then, when you’ve gotten to the “but what’s the problem” stage, can you have a real conversation about if that’s a problem worth solving, and if there are other possible solutions to that problem.
That 40-parametered roadmap I inherited was an example of this: it was a series of solutions the team had backed into, with a bunch of justifications for why we should build them. When we investigated further, many solutions were different ways of solving the same two or three opportunities we had. Once we rewrote many of the projects to focus instead on the opportunity rather than on the specific solution, we were able to consolidate different efforts across the company and give autonomy back to the executing team to iterate to the right solution by balancing costs, rewards, and risks.
So let’s unpack those rewards:
Reward 1: Expanding existing business (increase current revenue)
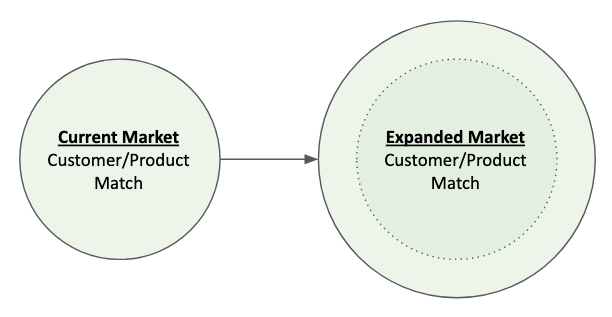
Expanding existing business is exactly what it sounds like. You already have some customers and sales channels, and your goal is to do more of that, to generate more revenue there.
At Dragon Blood Balm (a niche consumer product goods company), this meant focusing on increasing average order size (often by playing with price and promotions), increasing the number of orders per customer (through marketing and communications), and increasing the spend and subsequent reach/conversions of our advertising.
When I was at a B2B enterprise healthtech company, the types of projects that fell into this bucket included increasing our utilization volume (for cost-per-service activities), creating new capabilities that could be upsold to existing customers, and selling our existing platform to new clients.
However, increasing existing business often has an upper limit. Within the company’s area of healthtech, there were 300 or so major insurance companies that were viable sales targets. If insurance companies were our only business, then we would eventually hit a point of full market capture and no more growth might be possible. If we tried to maximize revenue capture by bundling or increasing prices for any single insurance client, they would get wise and eventually try to find unbundled and cheaper alternatives. Same for Dragon Blood Balm: there was a ceiling on how much we could increase the average order size and frequency given the nature of our products and pricing. As we approached those points, squeezing out further growth had a higher and higher cost to us with less and less efficacy.
That’s why you need to also think about Reward 2, entering new markets.
Reward 2: Entering new markets
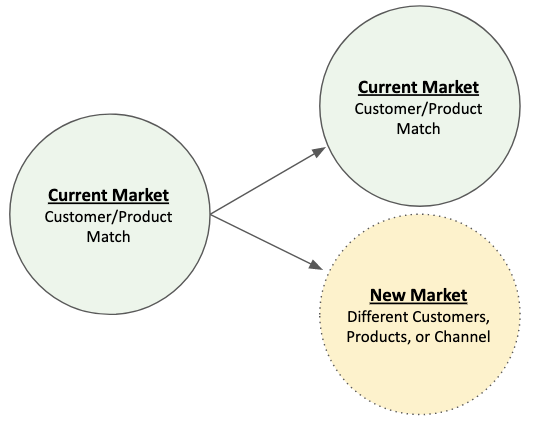
If increasing existing business is often a “do more, do better” of what you’re currently doing, entering new markets often requires doing things differently — including leveraging different people, processes, and products.
Because of this, it’s often harder to create new channels for growth than it is to make existing channels more valuable.
To continue with the two examples, at Dragon Blood Balm we knew that our existing product worked and had an audience. New business lines meant launching new products & new sales channels. New products allowed us to reach new people with new uses cases, but it required R&D efforts and changing our production process to accommodate different formulas. New channels such as wholesale (we were primarily DTC at that point) meant new (and potentially lucrative and recurring) revenues streams, as well as stability of order volume… but the tradeoff was that we needed to bring on and train a sales team to generate that business, we needed to invest in new packaging that would work for retail stores, and directing our marketing spend towards supporting retail partner success.
At our health tech company, this meant discussions about taking our product from the B2B insurance space to the DTC space, or expanding to other industries such as Pharma or hospitals. Each one would require a change in sales strategy, new product capabilities to support different workflows/integrations, and a change in collateral and ROI models we were pitching.
All to say, you often can’t fully take advantage of the scaffolding you’ve already built up when creating new lines of business. However, the upside is a much larger potential market and increased revenue opportunities, especially if you’re starting to hit the upper limits or diminishing returns on effort for your existing market.
For mature businesses, this is a logical next step in growth. But for new businesses, this is what finding product-market fit is all about.
Reward 3: Optimizing Profit Margins
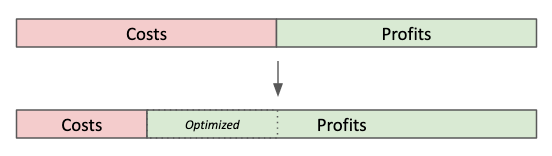
Operational costs are just as important as overall revenue growth. If you have a stable line of business, it makes sense to think about how to optimize operations so that you can decrease your cost of doing business. You can then capture this difference as increased profit margins or pass along the savings to customers to incentivize further growth.
To stick with Dragon Blood Balm, our optimization came primarily from taking advantage of scale effects: as our volumes of sales increased, we were able to order ingredients and materials in higher volumes and thus at a lower cost per unit. Our cost of production went down, which allowed us to invest in more marketing and advertising to increase sales, which in turn helped increase volume and decrease costs.
But optimization has three key drawbacks:
- It Creates Lock-In
Firstly, most optimization comes from a lock-in to some way of doing things, which can prevent you from being flexible in responding to changing needs and conditions. A good example is an assembly line: while an assembly line can increase throughput and decrease costs, it locks you in to doing the same thing over and over. A bespoke manufacturing process on the other hand might be more expensive and slower, but can allow you to create many different variations of a product to identify the right one to optimize for. Therefore, beware of premature optimization if you need flexibility. - It Needs Scale
Secondly, optimization itself is a reward only at scale. For example, if you have a SaaS service that engages a million customers per day and captures $50 from each of them, a 1% increase in conversions is an extra 10,000 customers and $500,000 in revenue. If you service 100 customers per day, a 1% increase is 1 customer and $50 reward, effectively a rounding error on any day. In the first case, a 1% increase can allow you to hire a few new team members, while the second case would allow you to buy coffee for a week, assuming you’re not ordering anything large or fancy. - It Has Strict Lower Bounds & Diminishing Returns
Thirdly, just like ‘expanding current businesses’ has upper bounds (you can’t capture more than 100% of your market before you need to expand), optimization has lower bounds: you can’t optimize to less than zero, and often hit diminishing returns vis-a-vis effort put in.
Meanwhile at the health tech company, one such misguided optimization effort was around our cost of delivering care services. We estimated that we could save at least 20 minutes per interaction through automation, and another 20 minutes of back office work through integrations with medical records systems. This would ultimately result in each individual on the care team being almost 3x as efficient. However, without increasing the volume of interactions we had, our efficiency gains would have been wasted. Moreover, the cost of building out that automation and integration was much higher than the efficiency gains we would have realized at that scale.
Other kinds of rewards
There are, of course, many reasons to do something. Any sufficiently large company might find itself with projects and goals around:
- Virtue signaling or goodwill
- Compliance and certification
- Things that are good for team morale
- Increasing customer satisfaction
- Protecting market share
- … and many others.
However, these often tie back to one of the three rewards we’ve already looked at: virtue signaling can help offset bad press and increase brand affinity and differentiation (which translates into revenue or price justification). Compliance and certification is often the cost of doing business with certain customers. Doing things for team morale is important if there is a morale problem that threatens business operations and thus is a stop-loss strategy. Increasing customer satisfaction is a proxy for customer retention and word-of-mouth growth. And protecting market share is important but it can turn into a process of mirroring your competition without understanding if those things add value or just sound great in the competition’s marketing. Moreover, losing market share is often a indicator that you’re not solving the right problems (or in the right way) for customers. Doing any of those things without proper justification turns them into cost centers.
Beware of things that look like rewards but aren’t
“The great public sector mistake is to judge policies and programs by their intentions rather than their results.”
- Milton Friedman
It’s really easy to confuse results for rewards.
Results are outcomes of your actions. Results show that something happened. But not all results translate into business rewards. Increasing click-throughs, improving engagement metrics, decreasing process running time, and increasing booked meetings are quantifiable results, but if you can’t draw a line between that and business rewards, there’s a high possibility that what you’re doing might feel valuable but actually isn’t.
This is important to understand this especially in context of all the layoffs happening in the tech world: the people, roles, and projects that survive (and get rewarded) are the ones that have a clear line between the work they do and the value they create from that work.
If this scares you, good! It should be scary. This is what accountability looks like.
Rewards are concrete and specific
"Consider the scenario. Two people have imagined two cute puppies. I assert mine is cuter. What do we do know? Do we have a cuteness argument? How can we? We have nothing to go on. The scenario is ridiculous. There's no way to resolve this conflict. Without a concrete and specific example of a cute puppy, there's no way to make progress."
- Ken Kocienda, "Creative Selection"
There’s a huge difference between “we should build Feature X because customers want it” and “we should build Feature X because its a cost-effective and low-risk solution to a problem that four clients are willing to each sign a $2 million contract to deploy, because it solves a costly headache for them”.
Bad rewards are generic and unclear. Good rewards are concrete and specific.
By being concrete and specific, you allow opportunities to be compared and pressure tested. You also create clear criteria for matching one proposal against another.
Concrete and specific success criteria naturally generate their own benchmarks to check progress against.
A good description of a reward should be able to provide dollar amounts, user justifications, and timelines. It answers the question of:
IF we solve [a] problem for [b] customers,
THEN we will see [c] rewards,
BECAUSE of [d] reasons.
We can approach this problem with [e, f, g] potential solutions.... and on the feature level:
I BELIEVE THAT [e/f/g feature description]
WILL [do something]
FOR [who is this for?]
BECAUSE [reasons].When rewards are not concrete and specific, that’s usually an indicator of hidden risk and uncertainty. It usually means that a lot of guesswork and assumptions were used (if there was any justification at all). It’s hard to compare abstract rewards and harder to know if you’ve succeeded in reaching them.
Which brings us to the next section, Understanding Risk.
4. Understanding Risk
“It is remarkable how much long-term advantage people like us have gotten by trying to be consistently not stupid, instead of trying to be very intelligent.”
- Charlie Munger
“Many people who appear to be famous risk takers are actually experts on capping the downside and imagining worst case scenarios.“
- Tim Ferris
Nothing is risk free. All roadmap decisions are decisions made about the future, and that is yet unwritten, unhappened. So the question is, how much risk are you willing to take on, and what can you do to decrease the risks you can’t avoid?
While almost all risks are due to not knowing the future, there are different reasons for not knowing what the future will potentially look like. Understanding different types of risks can help you plan for how to address them, and ultimately reduce the size of the risk.
The major types of risk are:
- Risk due to missing validation
(Such as missing information, you don’t know something you should know often resulting in picking the wrong problem/solutions) - Risk due to execution
(Such as process-related problems, failure when acting) - Risk due to dependencies
(Such as increasing problem complexity and scope, which means more things need to go right) - Risk due to probability & lack of control
(Such as when things are outside of your control and thus ultimately probability-based) - Risk due to change
(Such as black swans, paradigm shifts, and more mundane forms of changing requirements)
Risk due to missing validation
Risk due to missing validation is when you don’t know something that you should know. Most of the time, this manifests as “we don’t know if this is a good idea or not”, or as a lack of specificity/details about the rewards.

Luckily, this is also the easiest risk to manage:
- If you’re a new employee and you don’t know enough about the industry or the company, you can talk to internal experts.
- If you don’t know enough about customer behaviors and needs, you need to find ways to engage with customers. Talk to them, survey them, do over-the-shoulder observational studies. Learn good interviewing techniques that aim to uncover new and valuable information.
- If you don’t know enough about the market needs (people who are not yet customers), then you need to find ways to engage with those people. Events, surveys, paid consultations, cold outreach, and sales/presales tactics are great ways to engage and get validation.
- If you lack specificity, you need to drill down into why you lack that that. More often than not, it means that you haven’t spoken to enough customers or potential customers to be able to able to confidently propose a range of realistic numbers that you could measure against in the future.
One of the ways we evaluated knowledge risks with my team was to ask why someone was confident in their proposal and details. The level of validation someone could provide could easily be mapped to the chart above and provided a clear direction for where more validation was needed.
You don’t need to be able to predict the future to act, but you do need to have some good reasons for thinking a specific future is likelier than another future. The less you know, the more you expose yourself to uncertainty about the outcomes. Thus the work here is to reduce the amount of uncertainty — and hence the amount of risk — as much as possible by interacting with customers and potential customers.
The consequences of risk due to validation is usually picking the wrong problem or picking the wrong solution to the problem.
Picking the wrong problem looks like work that isn’t actually valuable, or working on problems that aren’t properly validated. It often happens when a market/opportunity is properly sized but isn’t validated against customer needs. The most immediately familiar example is Meta’s quest to “capture” the VR market early (and hence reap all of the benefits of owning their own platform). While this makes strategic sense, the problem is that VR doesn’t seem to be a problem any customer needs solved. There is not yet a great use case for VR, and Meta’s push into business applications such as Horizon Worlds flies in the face of their own logic for asking people to come back to the office for in-person collaboration.


Picking the wrong solution is when you identify the right problem, but you solve for it in the wrong way. To give a closer-to-home example, I fell flat on my face one time when I identified the right problem (increasing utilization) but proposed a solution that was a non-starter for the client (push notifications and marketing) because it ran afoul of regulatory rules against incentivizing healthcare services. Oops!
For any problem/opportunity, there are near-infinite possible solutions. Picking the wrong one happens when you cannot gain more information to increase the confidence between options.
The solution to risks due to ignorance is usually to speak with customers or other stakeholders and learn more about them, then to validate the solutions with iterative development and tight feedback loops. While it won’t help you choose the right solution, an iterative approach will ensure that you don’t overcommit to doing the wrong thing for too long.
Risk due to execution
As they say in Hollywood, “some ideas are execution dependent”. It means that the key success factor is how well a something is made. This makes sense in the movies — most ideas are narrative tropes that have been told hundreds of times. So the success or failure is dependent on how good that version of the telling is. Hence, it is execution dependent.
This is true in business as well. David Heinemeier Hansson from Basecamp makes the point that Basecamp is essentially a to-do list, which has been done hundreds of times by hundreds of businesses. "The vast majority of businesses succeed or fail on the basis of their execution and their timing." So if Basecamp succeeds, it is because they execute well.
And while you can fail because you chose the wrong problem or proposed the wrong solution, because most businesses aren’t making extremely novel and innovative solutions (despite what they’d like to think). So risk due to execution is the most likely challenge any team will need to deal with.
This is caused by people, processes, lack of follow-through, and incomplete planning.
At my last employer, we had a lot of risk due to execution because we were bad at shipping code. We had too much work in progress, we had teams with too many dependencies to be able to deliver anything on their own, and we shipped things with too many defects to get traction with users and clients — something I wrote extensively about in “When Everything Is Important But Nothing Is Getting Done”.
For others, risk due to execution might mean being slow at iterating through problems or making decisions. It may mean overspending on capabilities or overstaffing/understaffing in proportion to the work at hand. For others still, it might be an inability to actually get work done on anything that isn’t already in progress.
It also means being aware that success does not end with shipping something. In software development, too many product managers limit their attention to the software development process and are happy to completely hand off responsibility for getting their solutions into customers’ hands to the marketing, sales, and customer success teams. This is a mistake. Getting solutions into people’s hands is just as important as making the solution… and it’s also where you learn if the solution is successful or not, and how you get the feedback necessary on if you need to pivot.
I’ve seen more initiatives fail due to this lack of an action plan and rollout effort than I’ve seen in companies shipping defective code. This is because getting products into people’s hands is a hard problem. Remember: if you make something and no one uses it, that’s even worse than not making anything at all because of all the costs that went into it. So if your biggest risk is utilization, dedicate a fair amount of time to accounting for this risk.
Risk due to execution can be measured by the complexity of the problem/solution, the capacity (and available skill sets) to tackle that pattern, and historical patterns of delivery. Resolving it is about finding opportunities for process improvement, which is what frameworks such as DevOps, SixSigma, Total Quality Management and other operational excellence systems aim to solve for. It’s about how to do work better, rather than how to choose better work.
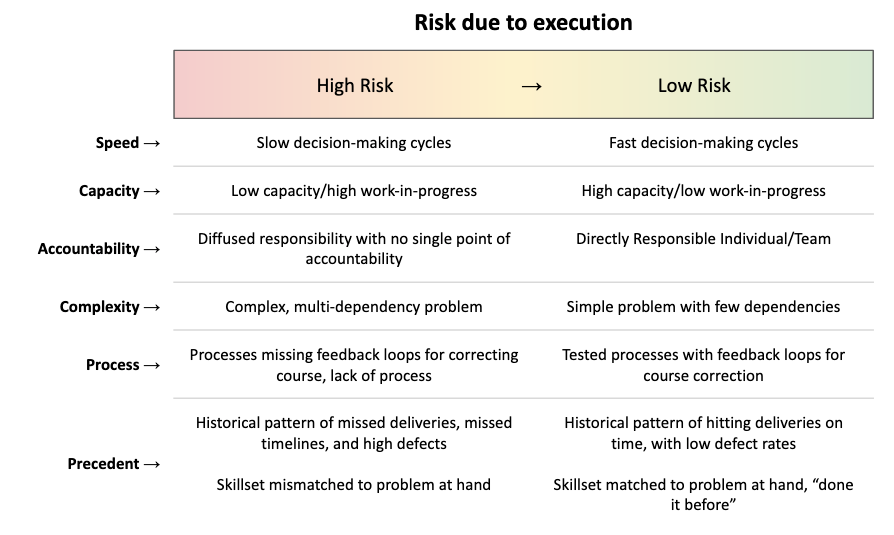
Risk due to dependencies
A corollary to risk due to execution is risk due to dependencies. Dependencies are like a Rube-Goldberg machine. The more things that are required to go right, the less likely it is that all of them will do so.
This is especially true when a dependency is actually a prerequisite. Annie Duke describes this quite well in her book “Quit”, when she talks about Google X’s Astro Teller and his way of evaluating difficult dependencies. Here’s the part, using an example of how to create a “juggling monkey show”:
Teller recognizes that there are two pieces to becoming successful at this endeavor: training the monkey and building the pedestal. One piece of the puzzle presents a possibly intractable obstacle in the way of success. And the other is building the pedestal. People have been building pedestals since ancient Greece and probably before. Over two-plus millennia, pedestals have been thoroughly figured out. You can buy one at a furniture store or a hardware store, or turn a milk crate upside down. The bottleneck, the hard thing, is training a monkey to juggle flaming torches. The point of this mental model is to remind you that there is no point building the pedestal if you can’t train the monkey.
… In other words, you ought to tackle the hardest part of the problem first. […] You already know you can build the pedestal. The problem is whether you can train the monkey. On top of that, Teller realizes that when you’re building pedestals, you are also accumulating sunk costs that make it hard to quit even as you find out that you may not be able to train the monkey to juggle those torches. By focusing on the monkey first, you naturally reduce the debris you accumulate solving for something that’s, in reality, already solved.
The dependencies problem can be modeled with simple math: let’s say you have a 99% chance of something succeeding, and it has one dependency (also 99% chance of succeeding). Your success rate is 0.99*0.99, which is 0.98, or 98%. But most of us aren’t working with things that have a 99% certainty rate and only a single dependency. Let’s say you have a project that seems 80% certain to succeed, but is dependent on three other things happening as well. One of those things is a 50% chance, another is 99%, and another is 80%. The likelihood of you succeeding is not 80%, but 31.7%. Even though every part seems likely, the final result is anything but. So if you have a dependency that is extremely high risk, it could tank your entire effort. You should focus on fixing that first, before embarking on anything else.
Which brings us to….
Risk due to probability
Risk due to probability is when things are ultimately outside of your control. You might select the right problems, the right solutions, execute them well... but still fail.
For example, if you’re working on a software problem, you may have full control over the outcomes. If you write a new script or optimize the existing architecture, you may see a direct result in say, higher throughput or processing speed. Conversely, if you’re working on a sales pitch, you might do ‘all the right things’ and still find that the deal is lost because you’re not the one making the buying decision.
Of all of the risks, probability is the only “formal” risk in the sense that even with perfect information, you still don’t know the outcome because that outcome is outside of your control.
Managing this kind of risk is about having fallback plans. Because you don’t have full control over the situation, you need to (a) understand the possible outcomes, their likelihood, and their impact, and (b) what your fallback plan is for the most probable and impactful ones.
Finance and gambling tend to have the most robust management models for hedging against probability-based risks. This includes tactics such as distributing and hedging bets against each other, creating options around black swan-like events, and bet-sizing criteria derived from probable outcomes and the availability of funds. To translate that into business terms, it means tackling multiple problems, having a premade plan for when things go wrong, and figuring out the right balance of cost-to-rewards to pursue based on existing runway and risk profile of the proposal.
Risk due to change
The last risk is risk due to change. Change over time is inevitable. Circumstances, budgets, people, and requirements change. You might learn new information that changes your decision-making calculus. Someone might pressure you to add something to the backlog. Someone might quit. A customer might have their budget slashed.
Each of these things (any many others) is a change in circumstances that you need to consider. By acting in the world and learning from those actions, you have an opportunity to proactively modify your business calculus for the better (including sometimes killing projects and sometimes doubling down on them). Conversely, when the change is out of your control you need to be reactive (and it’s more likely than not to be a setback).
The way to address risk due to change is by increasing speed or scoping projects smaller. This is something I wrote about in “When Everything Is Important”, but it’s worth repeating:
When projects are scoped too large, a few things happen:
(1) They take a long time to deliver, which means that work is locked up for long periods of time without creating value.
Said inversely, value is created only when someone uses the deliverable. Until something is shipped, zero value is created.
(2) They introduce the possibility — nay, the inevitability — of scope creep. Over time, more needs are discovered, customer preferences evolve, management changes, patterns are discovered, and so forth. The longer a project goes on, the larger the calendar window is for introducing a new request into the pipeline. The more requests are put in, the harder it is to keep saying no without coming off as difficult or uncollaborative or unresponsive to new business needs.
Said inversely, the shorter the project work window is, the less opportunity surface there is for scope change to be introduced. A two week sprint has a smaller surface than a two month project, or a two year epic. It also means that you can be more responsive to those requests because you’re working in shorter intervals. With the conclusion of each interval, you can change scope without it affecting your existing commitments.
(3) They introduce systemic problems in the form of people leaving (or new management entering), contracts/budgets/business needs changing, and so on. Each one of those represents a potential existential risk to a project’s scope and each one of those becomes much more likely the longer a project goes on (again: a larger calendar surface area).
How much do you need to know to be comfortable with a decision?
When I was a brand-new lieutenant, I asked my father, “How would I know if somebody that I worked for or worked for me was going to be a good commander in combat? ... How would you tell in peacetime?” He says, “You won’t. You won’t know because people have capabilities or coping mechanisms that in peacetime look fine, that doesn’t play well in war.”
Then I asked him, “Okay, when you’re in combat, how do you know?” He said, “Some people keep asking for more information and what they’re trying to do is drive uncertainty to zero so that there’s really not a question on the right course of action because you know everything.” But you can’t do that. It’s not achievable. So they become hesitant. They become tentative, and they become focused on getting more and more information to ratchet the uncertainty out of the situation and they don’t act."
- Ret. Four-Star General Stanley McChrystal
Risk is inherent in everything we do, and can never be fully removed. There are ways evaluate and understand risk, to manage risk, to document and create plans to address risks, but risk itself will always be present. Moreover, risks don’t exist in isolation. Risks overlap and compound. Risk due to not knowing begets bad decisions and hidden dependencies, each of which lowers the probability of things going right.
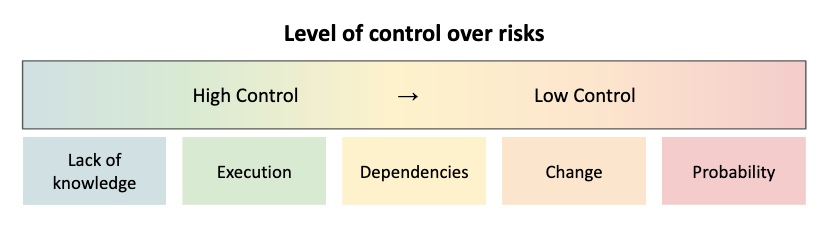
Some things you have more control over and others you have less control. The work is in figuring out what risks you face to understand what actions you need to take to manage or reduce those risks.
And most importantly, it’s hard to properly quantify most risks. Most of the time, attaching a number is a matter of guess work. It’s possible to have enough data to extrapolate the probabilistic risk of something, but most organizations that I’ve worked with or know about don’t have such clear and structured data over a long enough period of time to generate statistically significant numbers. So most people end up resorting to their intuition to say something along the lines of “we have a 50% risk of things not working out because of the team is stretched thin and priorities change weekly”. What does 50% mean, and how did you come to that number? When I hear that, I am less interested in the probability and more interested in the plan for if that happens. Ok, let’s the team gets stretched thin - what do you do now? Do you give up? What do you change?
Other folks will attach an exponential scale to the risks as a modifier for doing calculations. Itamar Gilad, for example, will use a a log scale of 0.01x for low confidence to 10x for high confidence as a multiplier for measuring projects against each other. My experience has been that this “math” is more often used to create a feeling of certainty than as a useful planning tool. Again, this is because the important thing about risks is not just how risky something is, but what you can do to change that risk profile.
Other times I’ll get asked, “how many people should I talk to before I know I have good information”? There’s never a good answer to this because it’s case by case. If your target audience is a specific customer, you might need to talk to two or three people. If you’re targeting an addressable market of millions, you should probably talk to more. (For what it’s worth, my rule of thumb is to talk to enough people that in your next interview, you pretty much know what the person will say. If you’re learning something new in every interview, then keep learning.)
At some point, you need to become comfortable with the risks to move forward to action; “Wanting more information is often just a form of procrastination” as Russ Roberts once wrote. Or as Cedric Chen wrote, “Action produces information”.
The question is, what is an acceptable amount of risk for you, your project, and your team? And that answer is all about costs and rewards.
5. Understanding Costs
“Time is the fire in which we burn,” says the poet. It is our most inflexible and valuable commodity, the one thing with which you should not be generous. Squander money, you may earn it back. Squander time, it is gone forever.
- Scott Galloway
Risk is an intermediary between rewards and costs. It’s all of the work that you need to do to ensure that the costs you put in generates the reward you expected.
To continue on the question of “how much information do I need to be comfortable,” this tends to follow a rule of proportionality. Here’s Ben Khun, CTO of Wave, on this proportionality:
The most important thing to remember when sampling from heavy-tailed distributions is that getting lots of samples improves outcomes a ton.
In a light-tailed context—say, picking fruit at the grocery store—it’s fine to look at two or three apples and pick the best-looking one. It would be completely unreasonable to, for example, look through the entire bin of apples for that one apple that’s just a bit better than anything you’ve seen so far.
In a heavy-tailed context, the reverse is true. It would be similarly unreasonable to, say, pick your romantic partner by taking your favorite of the first two or three single people you run into. Every additional sample you draw increases the chance that you get an outlier. So one of the best ways to improve your outcome is to draw as many samples as possible.
If you have high costs, then you need higher certainty and lower risk profile. If your costs are low and/or your impact is small, then you can get away with higher risk profile.
So costs are the last part of the Rewards/Risks/Costs equation and there are four important aspects for evaluating costs:
- Cost to build
- Cost to manage
- Opportunity costs
- Sunk costs, future costs
Cost to build
When people talk about building software, they often talk about how inexpensive it is (compared to ventures in manufacturing or retail) and how anyone can spin up a website and just get things going. But that's not entirely true. Running and scaling software can be relatively inexpensive, but building it is often very costly.
Software engineers are not cheap. A software engineer’s salary often starts in the six-figure range and most projects are supported by multiple engineers managing very different parts of building and running software. With that in mind, if you have an idea and need someone (let’s say a team of three or four engineers) to build it for you, you can easily be looking at a half-million dollar burn rate per year just from staffing engineering expertise.
This is also true for any proposal where you’re tackling a net-new business gain. As we discussed earlier, if you’re pursing a new line of business as the reward, then you often can’t take advantage of existing scaffolding, staffing, or infrastructure, and need to build up new scaffolding to support that.
This is the “cost to build”. When your cost to build is high and you have a finite amount of money, the consequences of not getting it right are also high. When your cost to build is high, you end up having fewer ‘shots at goal’: less chances to start over or pivot, less experiments you can run, less changes you can make in response to new information.
This cost to build can be estimated as an actual total dollar cost based on the time and number of people it takes to do something, and the associated costs of any supporting infrastructure or process development.
Moreover, the numbers on “cost to build” continue to run up until a project is delivered and in customer hands. Value is created only when someone uses the deliverable, so until something is shipped, zero value is created.
So if your cost to build is high, you need to find ways to lower it.
Decreasing the cost to build is primarily about playing games with scoping. By focusing on delivering to customers more frequently (for example, putting something usable into people’s hands every two weeks), you accomplish three things:
Firstly, you lower the cost per deliverable. In terms of time, effort, and dollar value, a two-week project is less costly than a one-month project, or a three-month project, or a two-year project. This is important because when you’re accounting for the value you created, you want to be able to say that you eventually made more value off a feature/project than it cost you to make it.
Secondly, you put a ceiling on the costs per deliverable. This limits the risk that a project’s costs will balloon and creates natural points for evaluating progress towards your goals. Otherwise, you might find yourself with long-running projects caught in a perpetual development loop than never find themselves ready for people to use them. Business-wise, that describes a money pit with a giant furnace at the bottom.
Thirdly, you create opportunities to learn from real-world customer behaviors and create natural points for evaluation against preset benchmarks. This real world feedback is essential for adjusting your risk/cost/reward calculus.
Ignorance about real cost-to-build is what allows teams to spend months working on small features and incremental improvements that deliver little real world value. This pain is especially acute for early-growth companies that are more dependent on venture funding rather than self-supporting revenue streams.
As an example, I once inherited a team that ultimately took two years (compared to an estimated six months) to deliver an enterprise contract worth $4 million. This team was composed of 12 developers, a project manager, a customer success manager, and two product managers. All together, their average salary was $150k/year. This means that the contract took the team $4.8 million to deliver it (not counting the hours put in by the sales team, legal team, and other supporting teams). At the end of the day, the project was a net negative reward of $800,000. Rather than being the “game changing contract” the company had expected to profit from, it ended up being a massive loss-leader for getting in the door for a large enterprise client. Legality aside, it would have been almost cheaper and definitely quicker to simply pay the client $1m to be their preferred vendor.
Cost to maintain
The flip side of cost to build is the cost to maintain. While cost to build is mostly for net new things, cost to maintain is racked up once something is out in the world.
The cost to maintain is slightly harder to calculate, because it needs to factor in:
- Continued costs of staffing and infrastructure costs against service delivery
- Continued management of defects and stability as something scales in use
- Increasing complexity of code/services which can decrease overall velocity and increase execution risks (such as bugs and defects).
Relying on adding “maintenance and support” tasks to preexisting teams can be dangerous if it ultimately increases their work in progress and slows down their ability to deliver.
Moreover, many maintenance costs continue (and sometimes grow) during the lifespan of a feature or capability. When you build something, you commit to keeping it supporting it until you get rid of it. For all future features, you also now need to consider how other things you might make will interact with this current feature.
A Digression on Technical Debt
Cost to maintain can also manifest as the “cost-of-shortcuts”. In managing cost to build, I referred to playing games with scoping as a way to reduce upfront costs and reduce risks through faster release-and-feedback loops. The value of getting real-world customer feedback on if something is worth doing or not always trumps the desire to write clean and well-architected code, especially if there is no certainty as to if that work creates any value (and might get scrapped).
But many cycles of this can generate significant technical debt which results in accidental complexity and eventually lead to bugs, defects, slower turnaround time, and cumulatively more technical debt. The solution is almost always rework, which can be hard for a team to get buy-in for.
My experience with tackling this technical debt was to rely on the same process of rewards/risks/costs as for any other proposal:
We kept asking "why is this valuable" until you get to the reward questions. It's often a few layers deep. Being unable to quantify the value of rework was often either a signal that the tech debt was an emotional grievance or that engineering leadership had no clear visibility as to the value of the work they did or the real size of the problem. Being unable to quantify the reward of the rework meant that we were unable to prioritize it against any other projects, and risked refactoring projects that took longer than the time they ultimately saved.
Opportunity costs
I’ve briefly alluded to “shots at goal” and “competing proposals from other departments” earlier. Outside of the cost to build and cost to manage is the opportunity cost of any proposal, which is to say — if you do “X”, what are thing things you can’t do anymore?
Opportunity costs take the form of:
- Budgetary limitations
I.e., in marketing if I spend money on one channel, I can’t spend that same money on another channel. - Capacity limitations
I.e., you can’t keep adding more work onto someone’s plate without their productivity diminishing. People can take on a limited number of projects at a time. - Timeline limitations
I.e., managing time-sensitive projects (such as when someone needs an immediate solution — as was the case during Covid) or limited runway (we have 6 months to make something valuable before we run out of time)
Being clear about opportunity costs helps to tackle the organizational problem of hidden work — such as when the work being done diverges from the work that’s on the roadmap. This can be due to benign reasons (someone helping someone else out) or otherwise (such as hidden work or when legacy projects continue because no one explicitly told them to end). Being clear on what isn’t going to be done gives people and teams permission to free up their capacity and say no to distracting projects, which is a major risk during execution.
Sunk costs, future costs
Lastly, you need to evaluate sunk costs and future costs. This one is tricky for most people.
Here’s Annie Duke in “Quit” again:
Richard Thaler, in 1980, was the first to point to the sunk cost effect as a general phenomenon, describing it as a systematic cognitive error in which people take into account money, time, effort, or any other resources they have previously sunk into an endeavor when making decisions about whether to continue and spend more.
The sunk cost effect causes people to stick in situations that they ought to be quitting. When deciding whether to stick or quit, we are worried that if we walk away, we will have wasted the resources we have spent in the trying. You might be experiencing the sunk cost fallacy if you hear yourself thinking “If I don’t make this work I will have wasted years of my life!” or “We can’t fire her now, she’s been here for decades!” Sunk costs snowball, like a katamari.
The resources you have already spent make it less likely you will quit, which makes it more likely you will accumulate additional sunk costs, which makes it again less likely you will quit, and so on. The growing debris of your prior commitment makes it increasingly harder to walk away.
The fallacy with sunk costs is that the money is already spent and can’t be rescinded.
Therefore, you need to focus on future costs rather than past (sunk) costs.
As an example, Duke refers to a public works project in California whose costs had ballooned to $10 billion dollars over the initial estimate. While there was plenty of outrage against the price tag, the project continued because “it was a sunk cost” and the only way to justify that cost was to complete the project. But completing the project — given the current status and known cost overruns — would be another $50 billion or so. So the decision about the initial $10 billion is really a question of if an additional $50 billion in future costs would justify that. If the original project wouldn’t have been approved by legislature at $50 billion, it’s cheaper to write off the sunk cost than it is to continue accumulating more future costs.
However, not all sunk costs are bad. A good use of sunk costs is to ask, “we already have x created, can we use it for anything?” To go back to the example of the $4m contract our team delivered at a loss, we were ultimately able to productize many of the customizations of the platform to sell it forward to other enterprise clients with similar needs.
6. Putting it all together: Speed, Cycles, and Safeguards
“The true method of knowledge is experiment.”
- William Blake
At the end of the day, nothing validates an idea better than actually engaging with reality. Again: “action creates information”. What ties together all of the risks, costs, and rewards is the ability to launch and get things out to customers. You need to engage with the real world, and not your idea of the real world.
This should be a “duh” sentiment, but people seem to forget it. More importantly, it’s central to everything we’ve been covering here:
- Until you’ve shipped something (put something out into the world and into people’s hands), you’ve created no value and you’ve created no opportunity to capture value. You’ve only run up the books on costs to build. And the longer something takes to ship, the more costly it is.
- The more costly something is, the larger reward it needs to reach in order to justify that cost.
- Any (and every) idea can be proven, disproven, or modified to be valuable or not, once it’s out there in the world. This real world feedback is the most valuable information you can get.
- So you’ll make better decisions if you’re able to use the real world as a guide.
- Which means that the faster you’re able to put things into customer hands, learn from customers and validate your ideas, and react to that, the faster you’ll get to better ideas and ultimately be more successful.
The organizations that succeed are the ones that engage with the real world, listen to its feedback, and react to that… rather than the ones that live inside their own heads and build without engaging with customers.
Which is to say:
- Doing successful work is a matter of going through cycles of learning-acting-learning-reacting.
- Companies that are able to go through those cycles with the most speed are the ones that will orient themselves best. This is true even if they start with the worst ideas possible, because the cycle forces you to learn and react. The company that takes six months of iteration to reach a valuable idea and the company that takes six months of research and arguing may find themselves in the same place, but the one that engaged with customers through iteration will have the benefit of additional real-world knowledge, experience, and a habit of getting things done.
- Both learning and acting need to have safeguards — criteria for determining if you’re on the right or wrong track, and what to do in either case. This prevents you from sticking with bad ideas for too long and ensures that you don’t get stuck in loops of action-without-learning or learning-without-action.
This means that Cycles, Speed, and Safeguards are the second-order impacts of risk, cost, and reward management:
- Cycles & Risks
Cycles allow you learn and adapt based on real world feedback. Cycles are a way of collecting more information to adjust your risk profiles. - Speed & Costs
Speed is the most effective way to keep costs down and decreases the volume of risk you will encounter. Coupled with quick movement through cycles it ensures that anything too stupid can get addressed quickly. - Safeguards & Rewards
Safeguards are generated by rewards and risks. Safeguards derivative of rewards are the KPIs and metrics that let you know if you’re on the right track or not. Safeguards derivative of risks are the “kill” or “adapt” criteria that lets you know if your likelihood of success will be challenged.
... and finally, the roadmap
All of this was around evaluating and understanding a single opportunity. But a roadmap is more than that: it’s a set of opportunities that you commit to working on, sequenced in the order that business capacity will be allocated to support them.
Understanding rewards helps you figure out if something is worth doing or not. Understanding costs helps you understand how much time, money, and people will be needed to get it done, and more importantly what that means you won’t be able to do. Understanding risks helps you validate the opportunity, figure out a tactical rollout plan, measure your progress, and cut your losses when you’re way off track.
Choosing between those — building the roadmap itself — is then the work of politics and negotiation between different stakeholders. Every company differs in its available runway, its appetite for risk, and the potential size of rewards it can tackle. Building a roadmap and getting buy-in is a matter of understanding those preferences at the decision-making level, and negotiating between them.
And as I stated earlier: if done right, those politics shouldn’t be too bad because what is on the roadmap matters less than how it’s on the roadmap. And that “how” is: with safeguards and iteration, focused on the opportunity and not the specific solution. It’s not to say that any “solutioning” should be banished from the roadmap, but that any solution is ultimately a tactic being tried on for size and other solutions may come and go before the opportunity is won or moved on from.
Lastly, it’s worth mentioning that roadmaps are ultimately a document of alignment and persuasion. The level of detail needed to evaluate all the opportunities is likely not the same level of detail that will get presented at the leadership level (opt for the abridged version and keep the other data in your pocket to pull out as needed), and it’s not the same document you present at an all hands versus during a team planning meeting. And while the level of detail may vary, it should always include the parameters of: potential reward, expected costs, and risks along the way. And once you’ve gotten buy-in to the problem/opportunity space, then you can add the tactics and safeguards in as part of your plan of action.
Phew!
That wraps up this post. Having reached this point, I hope that you can systematically understand how different risks, costs, and rewards can have implications on your plan of action, how to build systems for iterating through opportunities, and how those two things can help you identify the right stuff to work on.
In a future post, I’ll try to tackle some of the more practical implications of this — such as how to make useful product requirement documents and how product-engineering-and-design can best collaborate and avoid common anti patterns.
Thanks for reading
Useful? Interesting? Have something to add? Shoot me a note at roman@sharedphysics.com. I love getting email and chatting with readers.
You can also sign up for irregular emails and RSS updates when I post something new.
Who am I?
I'm Roman Kudryashov -- I help healthcare companies solve challenging problems through software development and process design. My longer background is here and I keep track of some of my side projects here.
Stay true,
Roman