The last company I worked for was a mid-stage startup with growing pains.
What had started out as a nimble organization able to create impressive software now felt stuck. Everything was high priority, nothing ever seemed to get completed, morale was low, and it was starting to coalesce into a learned helplessness where the only solution seemed to be resignation... and with high turnover in both the engineering and product departments, it was a solution that a lot of people pursued.
The worst part was that folks also remembered a nimble prelapsarian state, where things ‘Just Worked’ TM. No one was quite sure how we got there and there was no single unequivocally bad decision to point to. Like the proverbial frog in a slowly boiling pot of water, things slowly added up: a missed project here, a delay there, a new requirement uncovered...
You know this story. Maybe you’ve felt it yourself. It’s not an uncommon one.
So what do you do?
Table of Contents
- The Problem
- What We Did
- Step 0: Create Consensus That There is a Problem
- Step 1: Create a Unified View of All Existing Work
- Step 2: Create and Implement Criteria for Comparing Projects
- Step 3: Sequence The Projects & Commit to that Sequence
- Step 4: Getting Work Started, or “Start With Project Number 1, Work on One Thing At a Time, In Order, Until It’s Done”
- Step 5: Identify and Fix Your Organizational Constraints
- Step 6: Create A Clear Finish Line (Definition of Done)
- Step 7: Keep It Going (It’s a Process)
- Conclusion
- In Summary...
- Footnotes
Quick note: This is a long post and to make it easier for folks to read, I've turned it into an epub ebook & PDF. If you prefer to read it that way, you can download it here: https://www.dropbox.com/scl/fo/l9ocn9bdnrects1fgihi6/AM6UIkOB_t3ljfvthoUiT84?rlkey=1wru628h09l96gqmkdjumgxpn&dl=0
The Problem
When I started working on the "everything is high priority and nothing is getting done" problem, I caught a lucky break: everybody was frustrated and no one was pretending things were going well!
- We were trying to accomplish too many projects at the same time.
- No one understood their relative priority (everything was high priority).
- No one had any full visibility into ongoing, planned, and deferred work.
- Thus “prioritization” decisions were made with incomplete information.
- This routinely caused the team’s focus to change to whatever was the problem of the week (or to solve for whomever was yelling loudest).
- Without good visibility/observability, no one saw how projects shared dependencies across teams and departments. This led to too much work in progress (WIP) and an incorrect allocation of capacity and skill sets to projects.
- All of this resulted in poor velocity, poor outcomes, and company frustration. People were quitting left and right, and it was starting to turn into a negative flywheel of bad begetting worse.
BUT! We managed to fix this.
The disclaimer is that the process took us six months, required quite a bit of buy in, and wasn’t painless. But to give you the spoiler alert, we managed to get every project back on track, delivered, and reduced turnover to near zero (from a high of 50%).
So if this sounds vaguely like a growing pain you’ve experienced or are trying to fix, read on!
What We Did
Step 0: Create Consensus That There is a Problem
This might seem obvious, but the first step is to make sure everyone agrees that there is a problem.
When you start proposing solutions, you want the conversation to be about tactical execution and costs/trade offs, not whether this is a problem worth solving. That’s why I call it “catching an early break”. Everyone agreed that the problem — nothing was getting done and this was impacting delivery of contracts and features and overall growth — was real and was impacting every department, from sales to operations, product, and engineering.1
Part of this buy-in existed because we had cycled through two previous heads of product and one head of engineering. People were throwing their hands in the air and acting with learned helplessness: things just won’t change here. Because of that, I didn’t have to pitch anyone on the idea that things were broken. In fact, I volunteered for the role because no one wanted to take on a project that seemed doomed to fail.2
But these are the sorts of asymmetric projects I love and seek out. If you solve them, then there is a huge upside. If you don’t, it’s still a great learning experience and no one will hold it over you. After all, they’re already resigned that it can’t be solved. Even incremental progress/small wins are appreciated.
Word of advice: if you get the chance, always volunteer for such asymmetric bets.
Step 1: Create a Unified View of All Existing Work
To begin tackling the problem, we needed to understand its scope.
Given that a core part of the problem was that “nothing was getting done”, that meant starting at the very beginning: what is it that we’re trying to do? What were people’s expectations, ongoing projects, and wish lists?
For us, “work” hid in many places. We had technical work documented and tracked across multiple Jira boards. We had teams tracking some projects in spreadsheets. Other projects existed only informally. For example, someone would make a side channel request, and an engineer — wanting to be a good partner — would agree to help out without telling anyone one else. Then there were projects that were entirely engineering-initiated (refactoring, migrations) and not made visible to the larger company. Other projects existed as goals that come down from executives and their OKRs. Every team had a written wishlist of features, bug fixes, and major initiates that customers were asking for.
We organized all of this work in a giant spreadsheet. We captured the information indiscriminately. At the end of the day, there were 300+ projects for a combined product and engineering team of almost 40 people. After review, some projects ended up being duplicates, some requests were already closed out and others were no longer necessary. Still other projects turned out to be incremental pieces of a bigger pie.
With the full list, we ended up going through a few rounds of cleaning... this brought the list down to ~140 individual task/projects and ultimately rolled up into 20 thematically similar initiatives.
As part of that spreadsheet, we also added who was asking for what (key stakeholders), who was assigned to work on it, the status, if estimates were available, and the expected due dates (from a business-needs perspective).
For example:
| Project Name | Stakeholders | Urgency | Value | Key Owner | Dependency |
|---|---|---|---|---|---|
| Create Widget | Sales, Marketing | Jan 3 | $4m Client Contract | Team A | Needs Team B, C, and Pre-Widget Project Completed |
| Add User Configurability | Client Success | N/A | Less reliance on engineering for updates (estimated 15h/month, so $18,000 savings) | Team C | Team D needed for handling data updates |
| Build a bot to handle common inbound concerns | Operations | ASAP (No deadline though) | Remove the need for 3 FTEs ($250,000 savings) | Team A | Need bots framework completed, dependency on Teams B, D |
The goal was to create clarity and visibility of all of the asks, all in one place. This was a no-judgement zone. Our goal was to capture all of the work that existed or was planned or even desired. The mantra was: “if it’s not on the list, then it doesn’t exist.” Even though we knew the list was unmanageably large, we encouraged people to add more at any point. Nothing was too big or too small. Again: “if it's not on the list, then it doesn’t exist.”
This was the foundation for us to start an honest conversation about what we had on our plates, and how we would tackle it.
Step 2: Create and Implement Criteria for Comparing Projects
The second half of our problem was that “everything was a high priority”. “Indubitably”, as one says in response.
But traditional “prioritization” — the "high-medium-low" kind that comes out of the cereal box of most project management software — is one of the worst ways to organize work.3 There are three problems with this:
- "High-medium-low" doesn’t scale.
At four or more tasks, you’re forced to start doubling down on designations or to create subcategories of priorities. Eventually, you find yourself with a bucket of “high priority” projects wherein you don’t know what to tackle first. - "High-medium-low" prioritization lacks context.
It doesn’t take into account that something might be “high” for one person but “low” for someone else. This was as true inside of a single department as it was across the company. As a result, directors and managers would find themselves speaking past each other. For example: engineering would argue for refactoring the code base to improve velocity or transitioning to a new database as a high priority, while for product it was the development of new features, and for sales it was allocating capacity for new custom development contracts coming in. The deeper problem is that… - "High-medium-low" prioritization lacks enough detail to resolve conflicts.
It lacks a common language or framework for what “high” or “low” mean, and how to compare different priorities against each other. When most people talk about something being “high priority”, what they really mean is that the project has some combination of urgency and impact. Both of those are measurable or quantifiable parameters, but the informality of traditional prioritization glosses over them.
So what about objectives-based management as a bypass for prioritization?
Objectives are great! “Objectives versus priorities” is similar to “problem versus solution” thinking. Objectives tell you the goal and let you figure out how to get there. You set your own priorities and the only thing that matters is if the goal is achieved or not.
However, objectives are not a coordination layer. Even if you give everyone the same objective, there is no mechanism for figuring out which option to pursue to achieve that objective. And if you have multiple objectives — as we did — then you still run into the question of which one is more important.
The problem is that you need a conflict resolution and effort coordination mechanism. Aka, some criteria for clearly saying what takes precedence when two things are in conflict with each other.
So let’s go back to the idea that “all priorities are just some combination of urgency and impact”. When you commit to quantifying urgency and impact, you create a shared language as to why you’re working on something:
- Urgency is a byproduct of deadlines and dependencies. Do you need something tomorrow, or can you get it in two weeks? Is a project a dependency for something else to move forward?
- Impact is a combination of potential value created versus the likelihood of achieving that value.
These definitions cross departments and teams. Based on those two things, you can move away from the abstract, political, and fear-inducing “these are all high priority!” conversations, and towards a debate about the relative urgency and value of projects.
Of course, there were other considerations and parameters that we discussed. This included strategic value, R&D value, expected utilization, if there were contracts or sales deals out for that feature, and so on. But we eventually realized that all of this ultimately rolled up to the two criteria of urgency and impact.11
This wasn’t easy, mind you. Figuring out the impact and likelihood was something that a product management org would normally devote the bulk of its time towards. Not having that information was one of the failures of process we were dealing with, but we didn't have the luxury of putting everything on pause for a quarter to do a proper review. Instead, we (the leadership team) moved forward with some back-of-the-envelope math to estimate business value while the product team could continue scoping out more exact numbers in the background.
For those who are visually-minded, you can even graph it as a 2x2:

Step 3: Sequence The Projects & Commit to that Sequence
Talking about relative value was a back door into the “if you could only do one thing…” conversation. Literally: if you could only accomplish one thing, what would you do? Why? And once that was done, what would you do next?
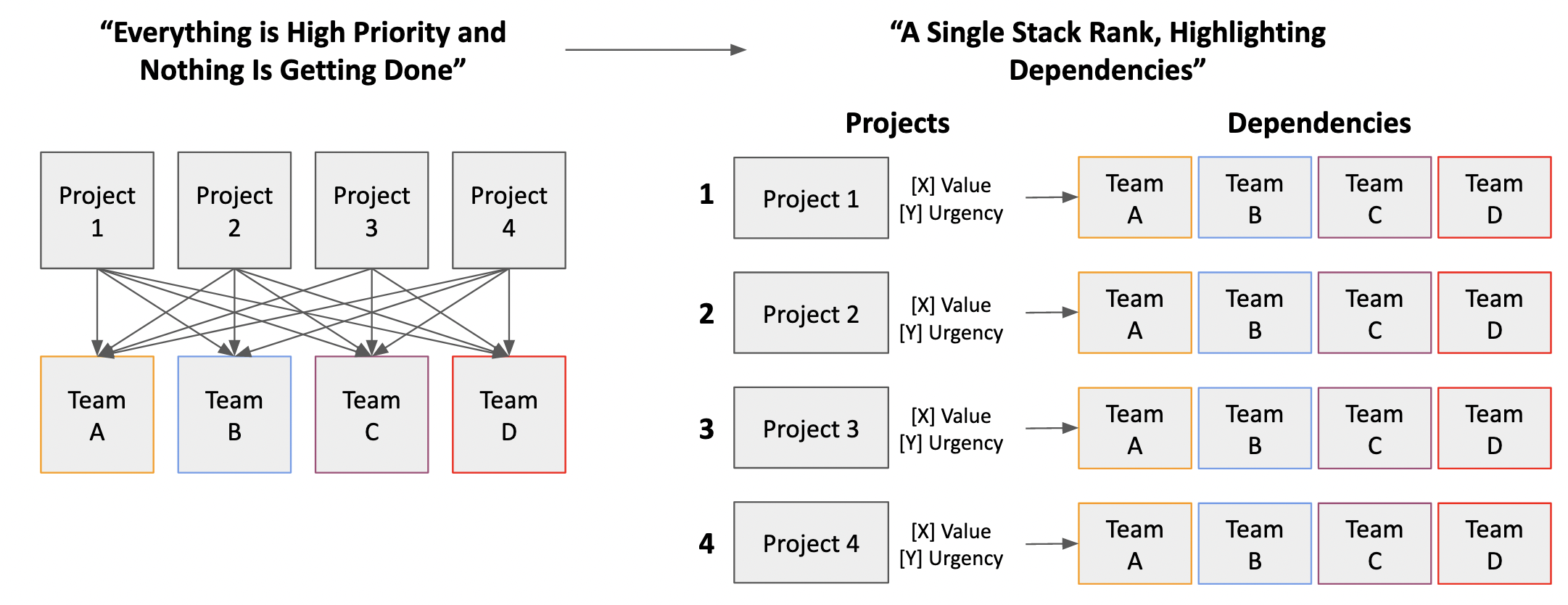
Once we had comparative metadata for all of the projects, we were able to organize projects against each other in a single stack rank, also referred to as a queue or sequence of work.
I do mean this literally. The end result of all of our work, research, and long and often painful meetings about what to work on was a “Top 10” style ranking of projects.4
And that was great!
It was exactly what we wanted. With projects organized in a sequence and agreed to by every department, it was clear to everyone (IC or Manager) what to work on: start at the top with #1 and work your way down. If there was a conflict between two projects, you could clearly see which one had the right of way.
This also became the framework for dealing with any new/incoming projects when anyone (upper management or other teams) came in with a “this is high priority, you must start on immediately!” type of hand-waving things-are-on-fire request. With a single stack rank, we could always ask: “Where on the rank does this fall? Is it higher or lower than [current project]?”
Because the projects were always relative to each other, we could — and did — adjust the stack rank regularly.
And to be perfectly clear, adjusting the stack rank continued to be a deeply political process even after it was created. This is because the single stack rank is an important and powerful — and hence political — tool for your company to organize work. It forces you to make clear and visible decisions as to what the most important things to work on are… as well as what won’t get worked on for a period of time. 5
Step 4: Getting Work Started, or “Start With Project Number 1, Work on One Thing At a Time, In Order, Until It’s Done”
Once there was a single queue/stack rank, we began work on projects starting from number one and working down the list.
This isn’t as straightforward as it sounds though.
For the number one project, we moved both heaven and earth to deliver it. We made sure that the number one project had a team with all roadblocks removed: they had full authority to commandeer whatever resources and attention needed to support the delivery of their work.
I mean this literally. We commandeered the entire company to deliver one project at a time, knowing that this radical unblocking would likely stall other projects.
This trade off was okay because the previous state of affairs was that nothing was getting completed. So given the trade off between delivering at least the number one thing versus nothing at all, it was a bargain that even the most skilled internal negotiators were willing to try.
So we did that. And more importantly, we accomplished that number one project. Then we moved on to the next project.
Of course, the whole product engineering team wasn’t needed for the number one project. As Fred Brooks pointed out almost 50 years ago, “adding more engineers to an already late project won’t make it go faster”. I’m not here to prove Fred Brooks wrong. It's really important to emphasize that we didn’t succeed by throwing more engineers on a project.
Instead, we treated it like a train going through a busy city: the number one project was the train, and all of the crossing gates in the city came down as it went by. The number one project didn’t need every engineer and project manager; what it needed was total coordination in pursuit of its completion. If someone or some expertise was needed, they were brought in. If something needed to get reviewed or escalated, no one got in the way. If another project had to wait, that was okay. To continue the train metaphor: we attached whatever cars were needed, blocked all other projects from getting in the way, and if something got in the way on the tracks, we went right through it.
Step 5: Identify and Fix Your Organizational Constraints
This was great, but a concern quickly started, escalated, and was repeated: “you’re a team of 40 people… surely you can do more than one thing at a time?”
It was fair: even though the one project we were wholly focused on solving was moving forward quite swimmingly, every other project was worse off than before. They didn’t exactly stop. They continued to lumber on but with more delays than before, as key team members were pulled off to support the number one project.
But as Ryan Holiday likes to say, “the obstacle is the way”. We embraced that pain. It helped us learn what our organizational constraints were — the specifics of our team, processes, and infrastructure that led to compounding inefficiencies.6
While organization constraints can often be specific to your organization, they tend to show up as similar patterns. Our company was no different, and we identified three major constraints:
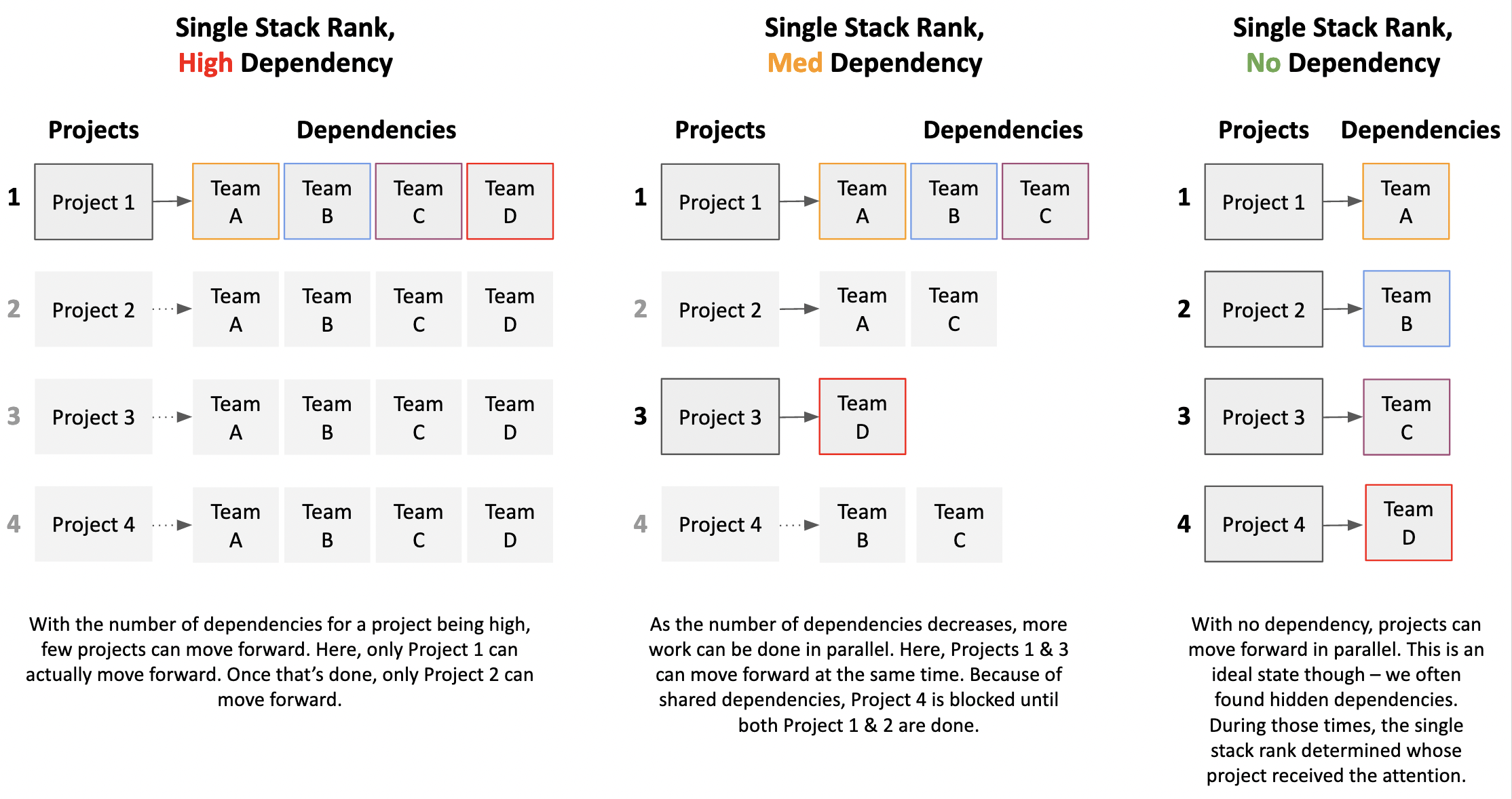
- We had high cross-team dependencies on most projects. No team could individually build and deploy any major project. Every team had a small hand in a project’s delivery and this made parallelization of projects painful.
- Because every team worked on every project, we had too much work in progress (WIP). This WIP was often hidden from view because the dependent teams were not immediately obvious.
- Our projects were scoped too large. The larger they got, the longer they took and the more risk and scope creep was introduced.
You’ve likely felt each these problems too.
Constraint 1: High Cross-Team Dependencies
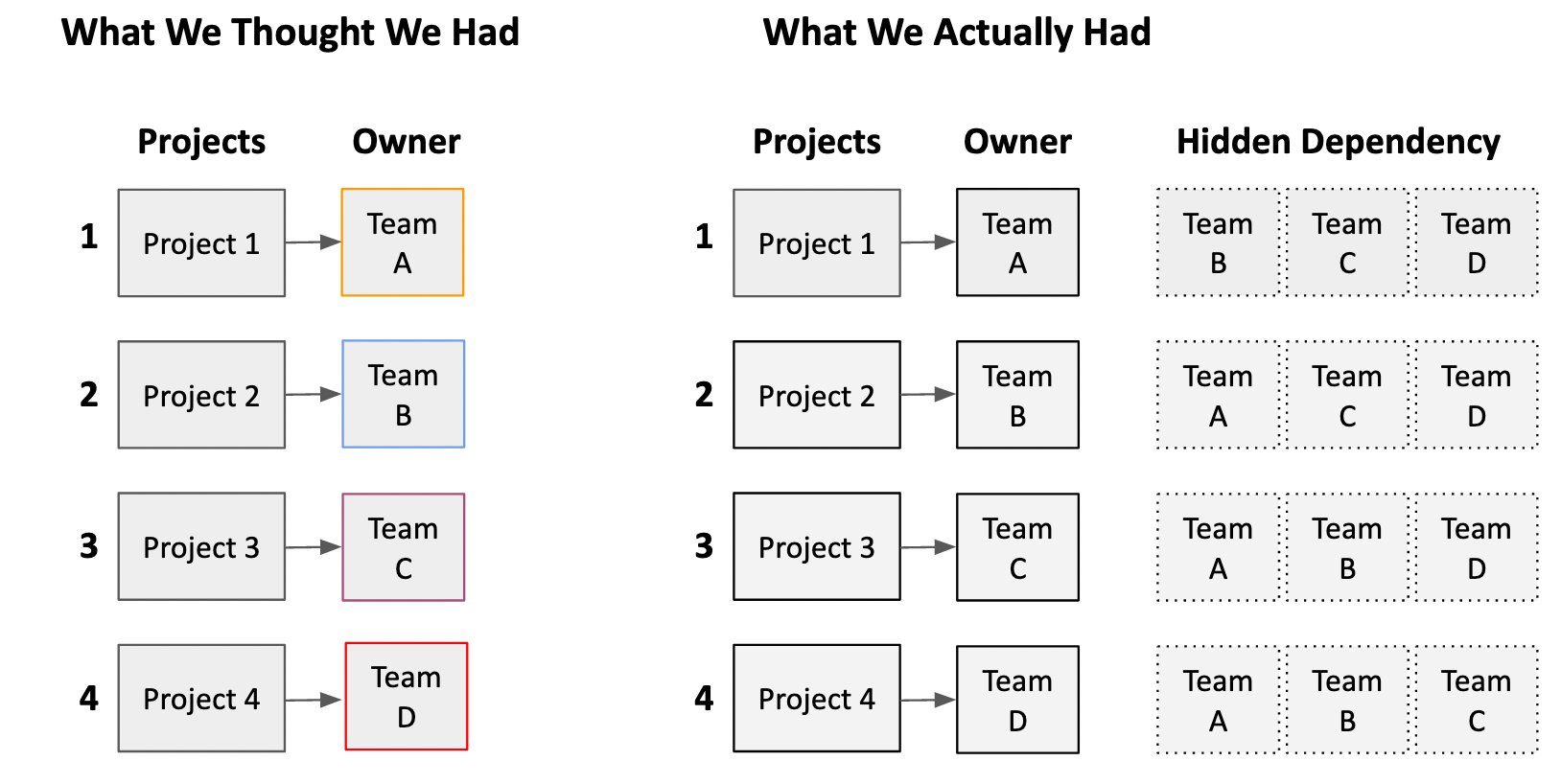
When we created a unified view of all the work, we also looked at who was responsible for delivering a project. While a single team’s name was often attached on paper, we knew informally — from conversation and from experience — that the lead team would often need to bring on other teams to complete a project.
As we deep dived into each project, we discovered that many projects required the full engineering team’s involvement. But on-paper, it looked like we were heavily weighted towards one or two teams while other teams had comparatively few projects they were working on.
This felt wrong. We took note every time it happened.
When a whole engineering team is required to deliver a project, it either means that the project is too big or that the teams aren’t organized for self-sufficiency.
For us, the problem was both. We learned that this lack of self sufficiency was strongly correlated with our team's misalignment to solving the current business problems.
At this point, our engineering team was oriented around feature development. These teams evolved to own their own architecture and as a result no single team knew the entirety of our platform code well enough to build any new cross-architecture features. Moreover, as those historic features became key “platform” capabilities, these preexisting teams became service gatekeepers or bottlenecks (they didn’t architect for self-service APIs, but that was a different problem).
To illustrate this: one team had been spun up more than a year prior to create a “user configurability” capability. This eventually evolved into its own configuration architecture. Eventually they owned all user configurability for any feature. As a result, anything new built that needed to be user configurable required that team’s involvement on a project. Because almost every feature needed that, they became a bottleneck.
This was the sort of hidden dependency we were starting to bubble up. None of the teams were independently able to deliver on their projects. Simply put, we had the wrong teams and org design for the business problems we were trying to solve. Not the wrong people, but the wrong allocation of people. It wasn’t a knock on the decisions that originally created those teams, but a reflection of a department’s org design not keeping up with business needs. The teams had instead evolved out of their internal logic of hiring decisions and local technical ownership.7
Uncovering these hidden dependencies led to the next problem:
Constraint 2: Too Much Work In Progress
If a team was working on multiple projects — sometimes due to hidden dependencies and sometimes due to simply having a lot of work on their plate — then their attention to any one project was split.
We learned the hard way that there was a direct relationship between the number of concurrent things you were trying to do and the increasing inability to complete any of them. This is called the “Work In Progress” (WIP) problem.
There’s a robust literature about why “WIP” causes projects to get stuck (as see the footnotes for a deep dive into it).8 The short of it is that WIP compounds due to four demonic patterns:
- Demon 1: Time Allocation Per Project
Time allocated to any one project goes down as the number of projects goes up. Let's say you work a perfectly efficient 8-hour day. If you have one project you’re working on, you can spend up to eight hours a day on it. With two concurrent projects, you might be able to spend eight hours on one and zero on the second, or split it as 4/4, or something else. If you have eight projects, then each one might get an hour, or some might get multiple hours while others get neglected. As more projects are taken on, the average time spent per project goes down. You can calculate this asHours in a Day (or days in Week)/Number of Projects. - Demon 2: Individual Switching Costs
Individual switching costs (time, productivity) between projects goes up exponentially as both the number of projects and thus the number of switches go up. This manifests as time spent in refamiliarization with a project's context and code bases, coordinating with other people, and other distractions that add up as the number of projects goes up. A single-hour block of time might end up wasting 50% of it on just the “meta” work of preparation. - Demon 3: Time Fragmentation
Time Fragmentation resulting from Demons 1 and 2 end up messing with the long unbroken blocks that “makers” need to do their work. A manager is able to move across a lot of projects in short blocks because they only need to understand the high level abstractions of a project. Meanwhile, a Maker/IC needs to understand all of the specifics and implementation details of the work and therefore time fragmentation takes a heavier toll on managing all of those details. For a deeper dive into this, I'll point you to Paul Graham's landmark “Maker’s Schedules versus Manager’s Schedules”. - Demon 4: With large cross-team dependencies, we also created an organizational coordination tax. Unlike switching costs (which can differ by an individual's level of involvement and expertise), the coordination tax is organizational and consistent regardless of the individuals involved:
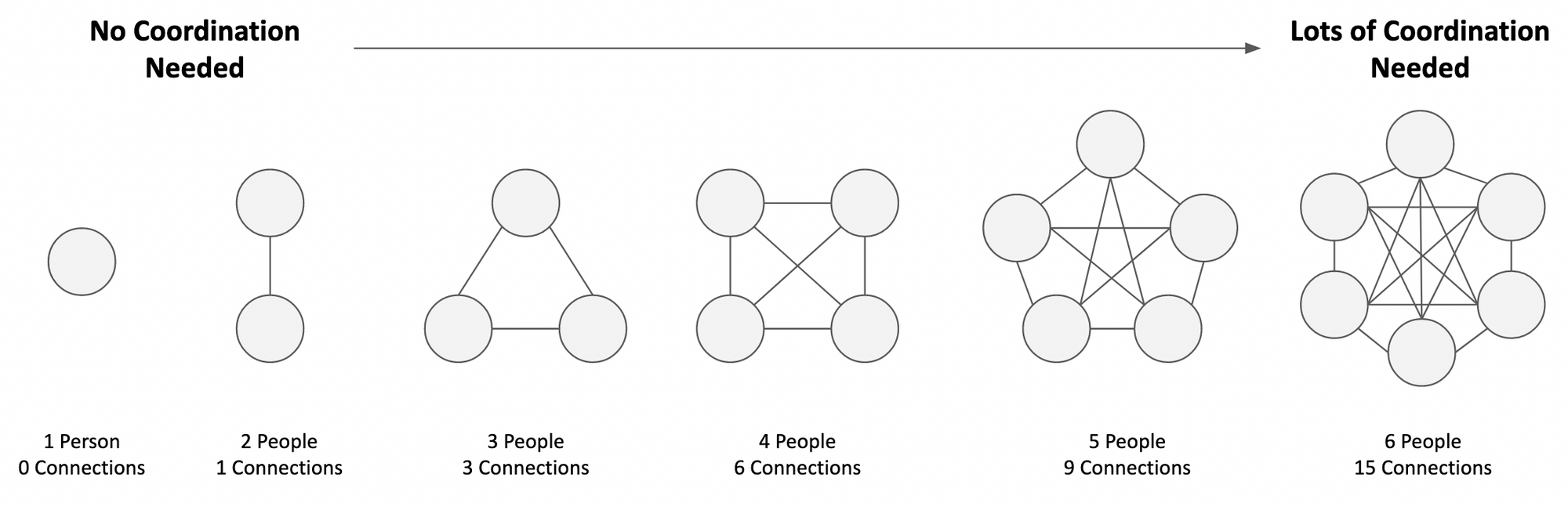
N*(N-1)/2 where N is the number of people. Put another way, the amount of coordination needed grows larger and larger as more people are added to a problem.Constraint 3: Projects Scoped Too Large
The last organizational constraint that we ran into was that projects were too damn big!
They were too big in many senses: the scope of work was too large; the delivery dates were too far out; and too many people needed to be involved in each project.
When projects are scoped too large, a few things happen:
- They take a long time to deliver, which means that work is locked up for long periods of time without creating value.
Said inversely, value is created only when someone uses the deliverable. Until something is shipped, zero value is created. - They introduce the possibility — nay, the inevitability — of scope creep. Over time, more needs are discovered, customer preferences evolve, management changes, patterns are discovered, and so forth. The longer a project goes on, the larger the calendar window is for introducing a new request into the pipeline. The more requests are put in, the harder it is to keep saying no without coming off as difficult or uncollaborative or unresponsive to new business needs.
Said inversely, the shorter the project work window is, the less opportunity surface there is for scope change to be introduced. A two week sprint has a smaller surface than a two month project, or a two year epic. It also means that you can be more responsive to those requests because you’re working in shorter intervals. With the conclusion of each interval, you change change scope without it affecting your existing commitments. That’s Just Being AgileTM. - They introduce systemic risk in the form of people leaving (or new management entering), contracts/budgets/business needs changing, and so on. Each one of those represents a potential existential risk to a project’s scope and each one of those becomes much more likely the longer a project goes on (again: a larger calendar surface area).
Addressing the Constraints
Implementing the single stack rank took care of the “what should I work on” problem.
For the scoping constraint, we began a slow process of breaking larger projects apart into smaller pieces. We didn’t move overnight from projects that took six months into two-week sprints. We weren’t ready for that. But those six-month projects were broken up into features that could take two months each, and that began to flex our collective practice of how to find smaller deliverable pieces within larger projects. After almost 9 months (and this included time to finish outstanding projects that couldn't be rescoped), we had transitioned — as a practice and as a tech stack that could allow for it — to most teams regularly having biweekly (or quicker) production deployments of value-generating capabilities.
And by mandating that the top sequenced item was the only thing people could work on, we temporarily solved the “too much work-in-progress brings every project to a crawl” problem. There couldn’t be too much work if only one project was being worked on at a time.
But that was an incremental step forward.
We still received a lot of pushback in the vein of “You have an engineering team of more than 40 people. Surely you can work on more than one thing at a time?!”
As I alluded to earlier, when it came to effective parallelization we learned the hard way that the size of your teams didn’t matter. What was important was the level of independence of your teams.
Fully independent teams were able to work on projects in full parallel to other ongoing projects. And as discussed, teams that had dependencies had their timelines bloated and estimates steamrolled through due to overhead costs of coordination, communication, and reconciliation amongst themselves.
By focusing our full team capacity behind the number one sequenced item at any time, we effectively created a pseudo-independent team that had all of the required resources to deliver the project. And it worked: the newly-unblocked number one sequenced items began to be completed with greater success. They were delivered faster, with lower defect rates, and with higher overall developer satisfaction working on those project.
That success created an illustration of how resolving our dependency constraints could unblock projects and built up buy-in for a broader department reorg to match our business needs.
Stage Managing the Reorg
The need for a team reorg was by far one of the most painful consequences of the single stack rank, but it was also one of the most important because it made a huge leap forward in our ability to parallelize work.
The change wasn’t easy; we continued to discover hidden dependencies as projects evolved and learned a lot about gaps in our architecture that prevented effective end-to-end delivery teams. We also learned where we had skill gaps and skill surpluses, and how fungible our teams were (or weren’t, in this case).
Most importantly, this organizational change ran up against the limits of the psychological safety of individual engineers and their management counterparts. People had concerns about breaking management relationships, about how it would affect their career tracks and goals from annual reviews, and how they would lose velocity initially due to having to learn new code bases and how to collaborate with new people.9
We managed this reorg slowly and incrementally. At the outset, we didn’t know the exact right organization we’d need – but we had a strong directional idea. Because of that, we wanted to reinforce that this was going to be a dynamic process where input from the ground was going to continue informing upstairs decisions.
The three key factors we were accounting for were (1) psychological safety, (2) building consensus and buy-in, and (3) solving for the "telephone" problem where information warps as it goes down the chain.10
The cadence of meetings per “change” implemented looked like this:
- Introduction/pre-selling
We would start by introducing the challenge we were working on and how we were thinking of approaching it. There would often be two or three of these, first in a small working group, then to all of the managers/directors, and then to the full team. Each time was an opportunity to test our message and refine it based on what elements seemed to trigger people’s defensiveness. - Workshopping through 1:1s
Then we would hold 1:1s with as many key team members as possible to work through all of their concerns and questions. Many people hesitated at asking questions in a public forum or had very specific questions with regards to what it meant for them personally. There was no way to scale those conversations. These 1:1s also allowed us to get ahead of influential senior managers who could have been saboteurs if they didn’t buy in. With them, we would sometimes have two or three meetings working through their concerns. We would also use this as an opportunity to do a “deep pitch” of the plan of action, again treating each conversation as an opportunity to battle-test both the plan and the communication of the plan. I can’t emphasize enough how important it was to work both out. - Final roadshow/sell
Then we would have a final “roadshow” set of meetings to roll out the final executional details of the plan. This was everything we had discussed in individual meetings, now communicated to everyone at the same time. Everyone got the same unambiguous message, reinforcing what we had already discussed twice earlier.
Later on, a new VP told me that there is a Japanese term for this — “Nemawashi” — of carefully laying the groundwork for any big change. I didn’t know that at the time, but I was familiar with the Lippit-Knoster model of managing complex change. There’s a lot to say about it — and it’s probably worth a full standalone post — but this illustration of the process was a valuable guide throughout the whole process:
Step 6: Create A Clear Finish Line (Definition of Done)
The last thing we did was to focus on the endgame: how work ends.
We did this because many projects have a tendency to evolve into “zombie projects”. If your definition of done is not strict enough, there is the risk that a project is closed out and moved on from... and then it magically comes back to life to be a distraction for you to deal with while you’re working on other things. This immediately leads to decreased throughput due to hidden work and a corresponding increase in WIP.
In zombie movies, the definition of done is that the zombie’s head is blown off or it is lit on fire and burned until nothing remains. We didn’t go so far as to light project managers on fire, but we did implement a strict criteria that identify a point where the project was considered complete.12 After that point, any new work or rework would have to be added to the stack rank as a standalone effort, ranked against all other projects we had sequenced.
The definition of done we implemented had three key questions for us to answer:
- Did it solve the user problem?
A common scope creep I've seen is shifting the finish line from solving one problem to solving a different problem. This manifests as “Yes, the user can do that thing now, but now we learned that they also need to do this other thing.” But that “other thing” needs to be a different project, not a shifting finish line for the current project. Depending on how important it is, you might prioritize it as the next highest sprint, but it’s important to draw a line between projects because there is a never-ending stream of “one more things!” that you can find yourself grappling with. - Was it deployed to production?
If it’s not in user’s hands, it’s not done. We had a lot of projects that were “code complete” but not deployed. They were sitting around just waiting to become zombie projects. We needed to include testing and production deployment because the initial “code complete” was usually only 25-50% of the work. During testing and deployment, we often found additional development work was needed (the “well it worked on my laptop” problem). - Has it been in use for a ‘long-enough’ period of time?
“Long enough” is a tricky space. What you’re looking for is some validation that (a) the feature is actually being used, (b) there is not a significant number of bugs or errors resulting from use, and (c) some validation that the usage is actually solving the problem you set out to solve (see the first criteria again). Depending on your data and feedback loops, this can be as short as a week but it should be as long as you need it to be.
Your goal with any project should be to solve user problems, not just to ship features. If you ship something that hasn’t solved the problem, then you haven’t actually completed the project and need to go back to the drawing board. That said, see Footnote 7 for a short caveat about organizational maturity... the gist is that it takes time for a company to move from being feature-oriented to being solution-oriented. If your org is still feature oriented, criteria (a) and (b) are still useful.
This post-code waiting period was painful in the beginning for us because teams felt like they were sitting around and waiting. We refocused that “unused” time towards planning, retrospectives, more reasonable working hours, occasional refactoring, and other meta work. It also allowed us to start moving the team's thinking from being development oriented (build more stuff) to solutions oriented (solve problems).
Building the feedback loops from users and data back to product managers and engineers to inform their “done-ness” was an important step in also increasing team satisfaction because folks were able to start to see the impact they made on the user experience and also on the company’s growth.
Step 7: Keep It Going (It’s a Process)
At this point, we had created visibility around work being done, sequenced that work (with organizational buy in), started to change our team structure to be solutions oriented rather than inwardly focused, began to resolve organizational constraints, created a loop for getting buy in and solving communications problems, and created clear finish lines.
It took roughly six months to make this transition and another three months to continue refining the process, but we were in a good place. Projects were unblocked. We delivered two major time-sensitive contracts… on time, and with historically low defect rates. Morale was up across multiple teams, which reflected in better satisfaction scores on employee surveys and more importantly on a radically reduced turnover rate (we went from a 50% turnover rate per quarter to something like 4% quarterly turnover, including zero turnover one month).
However, this remained an active process. We worked on each piece in sequential order, solving problems incrementally. At every step, there were people yelling about symptoms of the problem, trying to address the pain they were feeling without understanding what was causing the pain. At every step, there were leaders who wanted to cut ahead in the process and start on a reorg or start on taking on new projects... without addressing dependencies or WIP first. There's no magic bullet for those conversations: they required a lot of patience and talking-through as to why we were doing what we were doing.
The only advice I have here is to be vigilant to the creep of political decisions that led to the bad patterns in the first place, and be overly communicative with those people. Even though I felt like I kept repeating myself, there was never a single instance where I benefited from communicating less or when someone complained that I already told them something. More often than not, people had selective listening or were distracted during a conversation... so when I repeated myself the next week (and the week after that), there was constantly "new" information being received by the listeners.
I’ll repeat myself: those bad decisions and requests never went away and we constantly grappled with them. But the more progress we made, the more people trusted the process. It was still important to manage up and manage down each day — but we unblocked company operations and rebuilt trust.
That said, there will be a moment where this model no longer works for the company, and a new model will need to be implemented. The team structures will need to change again. The criteria for evaluating projects will continue to evolve. That’s natural. But as long as you continue to create visibility, manage WIP and other constraints, and continue building cross-department consensus, I think you’ll be fine.
Conclusion
This is a long post. But having read a lot of writing about how people have worked through challenges at work, I’m constantly frustrated when someone makes a blanket statement of “we implemented [x] and it solved our problem!” Why did that work? What were the challenges and contexts?
I wanted to highlight that there is not a “Just Do This One Simple Trick” solution to challenging organizational problems. These issues build up over long periods of time and form deeply held and sometimes unconscious patterns of organizational behavior. No one intends to build processes that don’t work, but they sometimes implement processes that incentivize the wrong things and over time, enough of that creates organizational log jams.
Moreover, it’s hard to predict what will lead to this problem, which is why I’m writing about how we got out of it, rather than into it. Your mileage may vary for these solutions, but I’ve found these patterns of problem solving to work across three different companies now, adjusting for severity and context.
These are also not permanent solutions. This is a process that needs to be managed. And there will also come a time in an organization when these processes will also ossify into patterns that begin to slow things down and prevent work from getting completed. Again — it’s a vigilant process.
Moreover, it’s a process that needs a full company’s involvement to keep it going. The changes I describe involved more than just the product and engineering teams. Our work was on behalf of the full company’s goals, so other departments started to become involved with our projects as well – we wanted every key stakeholder and decision maker involved to make the teams truly end-to-end. This included sales, marketing, operations, finance, and even our recruiting and peopleops teams.
During this time you would often hear me say that the core problem any department grappled with was not exclusively inside that department, but often manifested in their collaboration with adjacent departments. For example: the challenges our product management team dealt with couldn’t be solved entirely within product management, as they relied on engineering for execution. The challenges the engineering team dealt with stemmed from decisions being made on the product management side but also on the sales side. Sales felt pressure from finance goals and needed marketing support. Marketing needed better guidance from product management. And so it continued in a loop of dependencies. Former leaders who tried to control what was exclusively in their own domain would eventually hit a wall and point fingers at other departments as to why things did not continue to improve without attempting to find ways to collaborate better. The “magic” happened when we came together as a team and agreed to work concurrently in the same direction. So I guess a meaningful caveat is that none of this will be that helpful to you unless you’re a department-head, director-level leader, or above.
That said, it also took nearly a decade for me to be able to put my original university learnings and enthusiasm into practice in a role where I could control outcomes. So even if you read this and think “oh but I’m not in a place where I can implement something like this”, being able to understand behavioral patterns, being able to observe the cause and effect of decisions other people make, and trying to unpack the “why” behind why certain decisions are implemented is still an extremely valuable activity.
In Summary…
I’ve gone on for long enough. To sum it all up for the TL;DR crowd, here’s what we did:
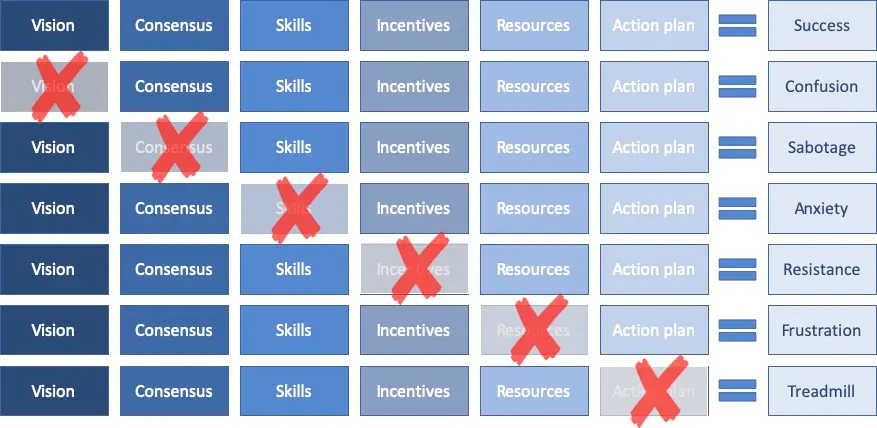
- Create consensus that there is a problem and alignment around pursuing a solution
If people don't agree, you'll get sabotage. If there is no vision, you'll get confusion. If the incentives aren't aligned, you'll get resistance. - Create a unified view of all existing work
We created a unified view of all projects. We organized all projects into a single spreadsheet to even know what to begin talking about. Without visibility, you'll constantly be blind-sided by "unknown knowns". This is basic situational awareness. - Create and implement criteria for comparing projects
We created a criteria for evaluating the impact and urgency of the work. This was the valuable metadata needed to help us evaluate the relative merits of projects. - Sequence projects & commit to that sequence
Once we had comparative metadata and evaluated all of the projects, we could begin sequencing the work. All work was sequenced into a single stack rank or queue. Every project was assigned a clear number for its position in the queue. This was a deeply political process as people had very strong opinions about relative value and therefore relative position in the queue. When people complained that we needed to have “multiple number one priorities”, we reminded them “that lack of focus is how we got into this mess in the first place”. - Do one project at a time, in order
Once there was a single queue/stack rank, we began work on projects starting from number 1 and working down. We made sure that the current number 1 project had a team with all roadblocks removed: they had full authority to commandeer whatever resources and attention needed to support the delivery of their work. - Identify and fix your organizational constraints
The pain felt by every project outside of the #1 priority was our guidepost to identifying what the constraints were. For us (and for many others), it was too much work in progress, high-dependency teams, and projects scoped too large. Addressing this required both process changes and a reorg. - Create a clear finish line
As part of clearing up the constraints, we created a clear definition of done that served to keep projects aligned to business goals and to prevent backsliding into unintentionally recreating the constraints we identified. - Continue this process
When new work and new projects were introduced, they were slotted in to the stack rank in their appropriate places. Rather than being viewed as a disruption, this was viewed as a desirable outcome because everyone had confidence that their work was always aligned with the highest value. No one was working on dead-end projects anymore.
The Results
- Higher velocity: projects began to be delivered faster.
- Higher quality of work: having the support needed meant less shortcuts taken, more testing, and better delivery.
- Lower coordination overhead:coordination and support problems were preempted by a single stack rank. It was clear to everyone how work weighed against each other.
- Higher satisfaction: less conflict and overhead meant more time working rather than politicking. Similarly, better throughput meant better results and feedback loops. Work just moved better.
Footnotes
Footnote 1:
Don’t underestimate the value of consensus in identifying what is and isn’t a problem. If there is an executive that doesn’t believe that the problem exists, it can undermine the entire effort. That’s why I call it a lucky break. Really, this is an essential part of change management and if you’re interested in all of the “parts” of what makes change management work, the Lippit-Knoster model of managing change management has been a candle in the dark for me (and I talk about it more in the "Stage Managing the Reorg" section).
Footnote 2:
How doomed? Well, this was the congratulations I was sent when the CEO announced I was taking over: “good luck, it’s your funeral”. Another one read: “congratulations on the battlefield promotion, your bloody garb awaits.” Yay!
Footnote 3:
Here's what I mean by out of the box. Here is Monday.com's promotional materials:
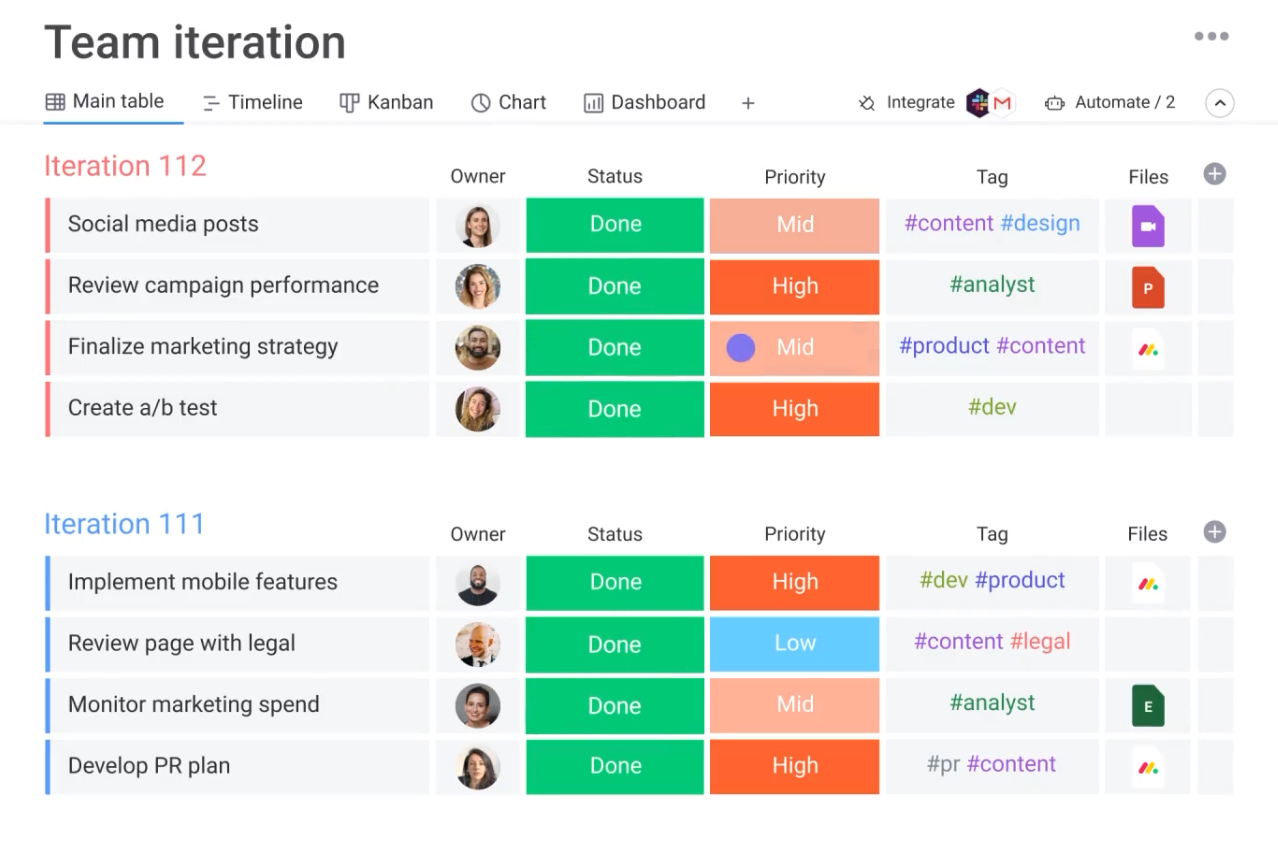
Look at all of that High priority work! Are you going to review campaign performance or create A/B tests, or implement mobile features, or develop a PR plan? I’m not picking on them; the three-option “High-Medium-Low” is a default of almost all project management software.
Footnote 4:
I want to emphasize how "not easy" it was to get to the final stack rank. We debated the relative merits for weeks. It took a long time because we had never done it before. But for anyone struggling with this, there are a few ways to address it. One option is make an executive call (which is effective but it doesn't exactly build a collaborative environment). Another is to weigh "value" as an absolute metric to prioritize for. Another option is to point-rank projects, where everyone gets 100 points that they can distribute across their preferred projects and you rank projects by their cumulative sums of points.
What we found valuable was to also have a moderator for the conversations. At times when we were going back and forth on one project, I also found it helpful to step back and loosen my personal ego: if we kept going back and forth on whether something should be #3 or #4, it really didn't matter. The goal of this process was that we were trying to make sure all of the work would get unblocked, and a single position wouldn't be a huge difference in execution. For sake of building trust and showing faith in the process, I was happy to let the other teams get their wins in.
Footnote 5:
To make this cultural change clear, we also pushed team members to move away from talking about “Priorities” and “Prioritization” and to talk about “Sequencing” instead. Language matters.
Footnote 6:
Constraints — or bottlenecks — are an interesting beast. There’s a robust literature around this, but the short of it is that you need to identify your bottleneck and make improvements at that bottleneck. Any improvements made after the bottleneck wouldn’t create value. Any improvements made before the bottleneck would only make the bottleneck worse. Here’s what it looks like:
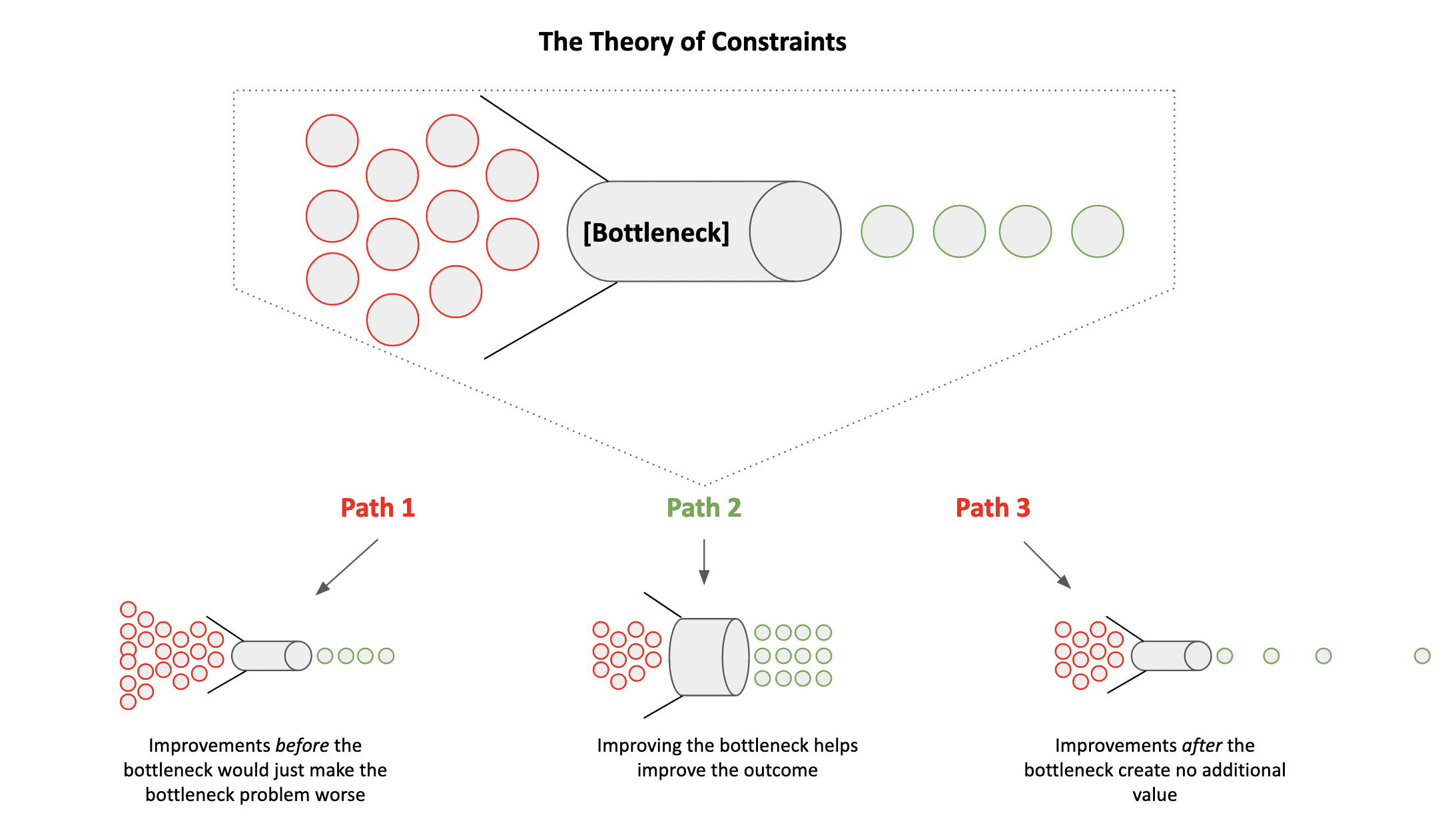
Identify what your bottleneck is, and focus improvements there. If you don’t know what your bottleneck is, then follow the stuck projects step by step. The places you feel/see pain are often related to the bottlenecks. Lean into that pain as your guide.
Footnote 7:
Painting in broad strokes, there are three types of software teams:
Delivery Teams
- Standalone teams with no relationships outside of the engineering organization... think dev shops.
- No relationship between features and outcomes, more of a requirements-driven first in, first-out model of work.
- These can be independent in delivery of work but lack enough context of business needs and outcomes to be fully operationally independent.
Feature Teams
- Output-focused cross-department teams — think owning a group of features such as a “chat stream” or “feature x”. They partner with other departments (such as design, product management).
- Ownership of one feature and supporting role for many outcomes.
- As domain experts/owners, these teams eventually become a dependency for others because a product is not a collection of features, but how those features come together to solve users’ problems.
Outcome Teams
- Cross-department groups empowered to achieve outcomes — think a team tasked with delivering a KPI such as user engagement.
- Ownership of one outcome and however many features are necessary to achieve that.
- These teams work well when they are full independent (including presence of other departments' stakeholders) and can work on many features on an as-needed basis.
Generally speaking, you want to be aiming towards the third option, Outcome Teams. This is because this is the most bang-for-your-buck type of team organization as they are most directly tied towards driving business outcomes (hence the name).
However, their feasibility is limited by organizational and product maturity. In our case, we lacked product maturity to make that happen without relying on a number of intermediate steps. Our product had major capabilities gaps upon which all outcomes were dependent, which - if we had organized immediately around outcomes teams — would have created duplicate efforts by the teams to solve for those gaps.
To illustrate this, let’s say you are an enterprise services chat app and you have two outcomes: one was to drive more consumer engagement and one to increase agent efficiency. A core component of both of those outcomes might be reliant upon automation — let’s assume that by bulk-automating sending messages, you both make agents more efficient (take work off their hands they were doing manually) and increase engagement (by scaling the work they were doing to be able to reach more people). In this case, two outcomes driven teams would overlap in building the same thing (automation, a key platform gap).
For us, this meant that we couldn’t have outcomes-based teams until we had solved for these capabilities gaps first. So we re-organized feature teams (see Footnote 9 on more reorg details) as an intermediate step and only later reorganized purely around outcomes.
A final reminder to add here is that just because a team is not outcomes oriented, doesn’t mean that outcomes were not a key component of measuring the value of features in development. It’s just that the relationship between outcomes to features in an outcomes-team is one-outcome-to-many-features; in a features-team, it is many-outcomes-to-one-feature.
As with all things, your mileage may vary. One of the reasons why our previous product department had imploded and we had such high turnover was because the previous leadership tried to pivot to outcomes-driven teams too quickly. This created a mismatch between the product department and the engineering department and both felt like they couldn't work with each other and achieve their goals. Eventually, people started to quit in frustration.
Org change is hard!
Footnote 8:
To go through the depth of why Work In Progress is an issue would require more detail than I can do justice to here. While I might do a separate blog post on what it looked like for us, in the meantime I encourage you to read the following:
- The entirety of “ The Phoenix Project “ and “The Goal” is an homage to limiting work in progress and finding the key constraints in your production capacity (in our case, the production of code for a software company).
- Will Larson on modeling “Why Limiting Work in Progress Works”
- More on Limiting WIP
Footnote 9:
To add some color and nuance here, building on Footnote 7: at the time, our teams were designed to be feature aligned — for example, Team A might oversee configurability, Team B might oversee consumer interfaces, Team C might oversee data infrastructure, and so on.
When this structure was created, it made a lot of sense — those were the problem spaces for the company to build out. However, those teams ossified as the company grew. That ossification was led by a totally normal process of maintenance, incremental hiring to shore up expertise, and the fact that people formed good working relationships together.
But over time, it was no longer aligned with our company’s priorities. If we needed to build a new feature, it required work across Team A, B, and C (and D, E, etc). The old structure did not align with the new problems. For example, you might need to build a new “bot” but that would require working with the data team, working with the consumer interface team, working with the agent interface team, working with the configurability team, and so on. This was the case for all new capabilities and projects we needed to work on.
A radical “just pull the band-aid off” reorg had been attempted a year earlier but it led to a lot of dissatisfaction and turnover. Management then back peddled.
This time around, we took an incremental approach to the transition by creating temporary “Task Forces” that brought together individual subject matter experts across all teams to temporarily work on a project. While it was still painful, it let the preexisting teams mostly keep their work moving forward (losing one person was a natural part of team turnover, while disbanding a team was much more disruptive), while also building the appropriate level of end-to-end independence for the Task Force to be able to deliver a project without being blocked by any other team.
Coloring it in the language of ‘temporary task forces’ gave ICs psychological comfort to stay or volunteer for these projects and build new relationships/expertise, while it gave management the flexibility to move things around and to not overcommit to any single change. Some of those task forces were truly temporary, while others eventually became long-lasting teams.
Eventually, there will be another inflection point where those teams will be challenged, but that’s a natural part of the circle of life, isn’t it.
Footnote 10:
Information has a tendency to lose bits as it travels along, and so it was important for us to shorten that chain as much as possible. We did this partially out of a "do things that don't scale" approach to solving the problem with whatever means necessary and partially because this was too important to mess up.
For those who haven't realized just how problematic this is, I encourage you to dive deeper into the following:
- Dan Luu's twitter thread on Microsoft Azure's communication practices
- Eugene Wei's blog "Compress to Impress"
Footnote 11:
After I published this post, there was discussion on Hacker News on how Tech Debt should be handled in situations like this. We had some intense discussion internally about how to handle tech debt, where it belongs, why it happens, and how much time we should spend on it. Our team went through 3 stages with regards to working on tech debt:
- Stage 1: Before I joined, tech debt (and resolving defects) were not prioritized by the prior product management team. This led to a near-revolt by the engineering team where they basically hid tech debt work from the rest of the company.
- Stage 2: When I just joined, leadership tried to course correct and it led to an executive mandate for 20% of time to be allocated for working on tech debt.
- Stage 3: As we went through this process, we netted out on that "tech debt" – regardless of why it exists (because of wear and tear, because of compounding complexities, because of of bad decisions and shortcuts to meet deadlines, because of outgrowing old requirements, and so on) was often requested and prioritized because it created some sort of value for the team. A lot of engineers pushed for refactoring projects and solving for other types of tech debt because they felt it was worth doing. The problem is that most engineers stop there.
We pushed engineering managers to quantify the value and urgency of tech debt projects they were requesting. This value was often expressed as cost savings due to increased efficiency. Once we had that, tech debt projects could be (and were) accurately sequenced against every other project on the backlog.
In terms of measuring value, we used a few guideposts:
- We kept asking "why is this valuable" until we got to the money questions. It's often a few layers deep. Not being able to get at that (missing an ability to quantify) was in itself something that engineering leadership needed to work on. After all -- how can you prioritize between two things if you can't figure out what value they create?
- Most engineering teams know that they might be able to save some time by refactoring. We often resorted to back-of-the-envelope math of using the average hourly cost of engineering effort and used that as a multiplier for time saved by a project's implementation. You can take it a step further and subtract the cost of working on a project from the time it ultimately saves you to remove "dumb" refactors that take longer to deliver than time they save.
- If you can't get to a tech debt's value, that's a red flag as to if it actually creates value. This was true for features and business requests as well. We also said no to features that "felt good" but ultimately created zero value (some redesigns included). "Rewriting something in a new language" because a new Sr. Manager with strong preferences joined the team was a big culprit of these sorts of projects.
- We also often asked if a tech debt project needed to be done independently of other work, or if it could be included as part of a new feature that we were working on. An example was that one team pitched rewriting a microservice because it had no API. On the other side of the company, we had a project to get rid of that feature entirely and replace it with a different functionality. If tech debt projects were handled entirely within the domain of engineering, we would have spent weeks rewriting something only to throw it away a month later. Hence the need for bubbling tech debt up to the single stack rank, and thus treating tech debt projects the same as any other project we were working on.
There's a lot of strong opinions about tech debt out there, but what it boiled down to for us was that we had a limited pool of time and talent (engineering) to work on any projects that came up. Any project taken on was a different project not taken on.
Footnote 12:
I'd be entirely remiss if I didn't caveat the difference between internally initiated projects and client contracts. We eventually built up a fantastic client-facing team that was able to apply similar "done-ness" criteria to client work as well.
This may sound rudimentary, but we implemented a more robust discovery process for understanding client needs and the explicit deliverables we would be able to bring to the table. The key element here was that there's often a big difference between what a client says and what they want. Not only that, but we worked with large clients who had multiple levels of beurocracy and their own games of telephone. Sometimes a "requirement" would make it to the table and no one had any idea why it was actually needed or requested. Other times, the client would propose "solutions" that took on a life of their own as it went through the chain of command and got to us. Middle managers might add some additional clarifying details or clean up the design as it passed hands and the "solution" wouldn't actually solve for anything – we built multiple such features that got zero use. So by going back to the client and understanding what problem they were trying to solve for, we were often able to suggest lighter weight solutions and also learn more about their needs.
Then we locked those definitions into client contracts, and implemented a standard change order request process to handle any scope creep. Once we did that, scope creep turned into a revenue-generating process rather than something we had to do at risk and for free (much to the team's frustration and at large risk to our contractual deadlines).
Thanks for reading
Useful? Interesting? Have something to add? Shoot me a note at roman@sharedphysics.com. I love getting email and chatting with readers.
You can also sign up for irregular emails and RSS updates when I post something new.
Who am I?
I'm Roman Kudryashov -- I help healthcare companies solve challenging problems through software development and process design. My longer background is here and I keep track of some of my side projects here.
Stay true,
Roman