When I first set up my Ghost installation on Digital Ocean, I noticed that it would periodically crash and give me 502 'unreachable' nginx errors. Sometimes, simply restarting Ghost would do the trick – other times, CPU utilization would go so high as to render even the console access unusable.
Digging around in my analytics and in both Ghost and Digital Ocean forums, I learned that this wasn't uncommon. While I had experienced this issue on AWS as well, it didn't seem to happen as often – probably due to different default server configurations and some autoscaling controls (that were partially the culprit for driving my costs up).
So what was the problem?
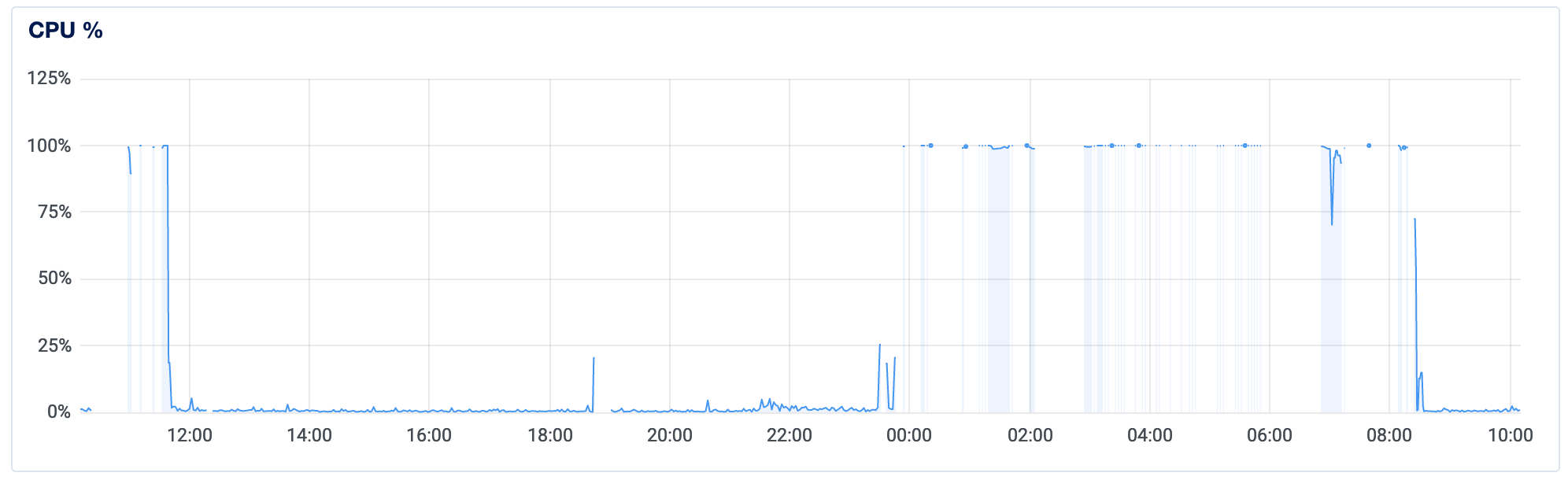
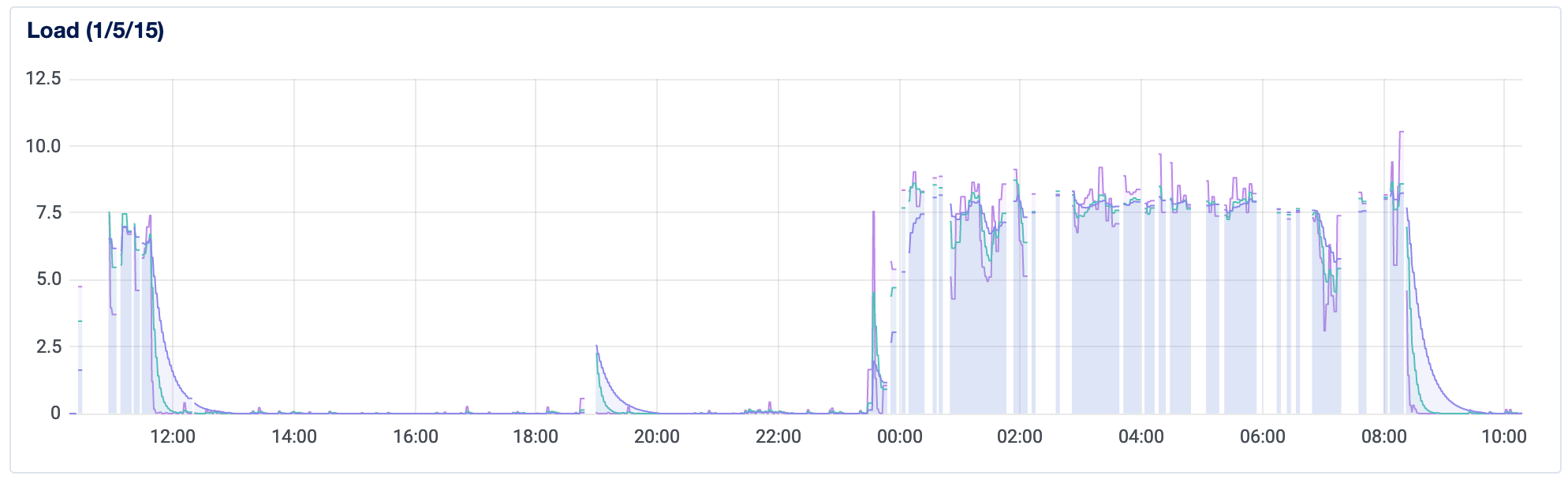
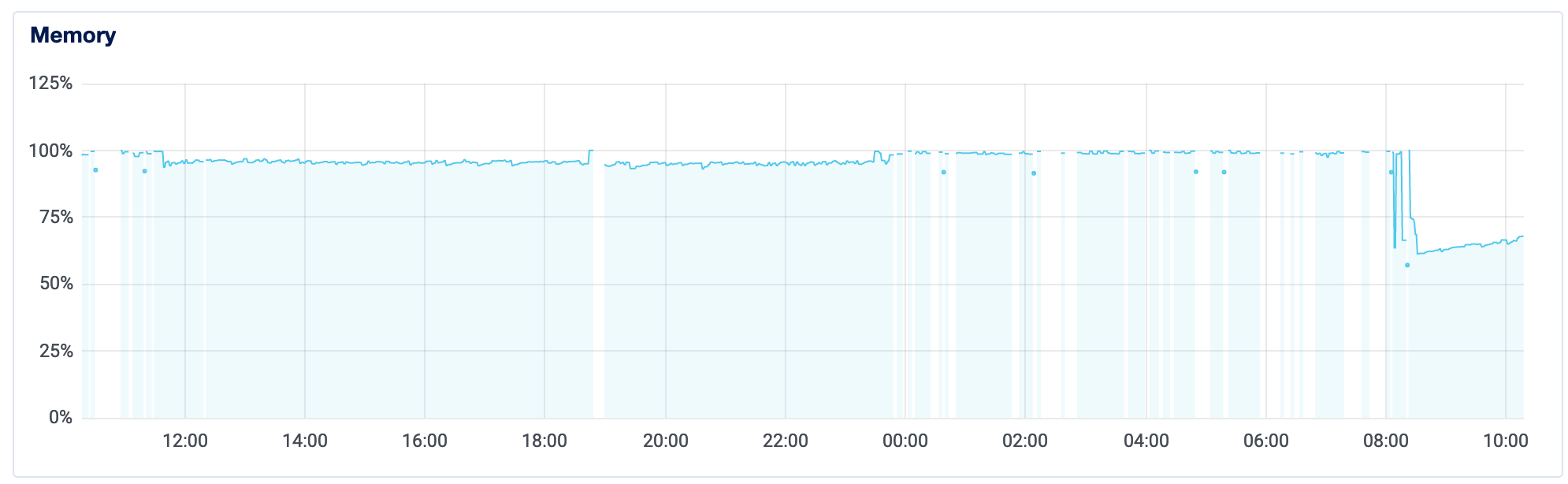
Looks like my CPU utilization – which normally hovered around 1% – would suddenly spike and then crash the server. During times when it was at 100% (or blank), it was entirely down and unusable. Load and Memory showed similar patterns. Hmm.
To try to understand more, I ssh'ed into the console (ssh root@[your_ip_address]) and then used top -c to see what was going on. My results looked something like the image below, with snapd taking up the majority of the processes and mysqld spiking up every couple of seconds as well.
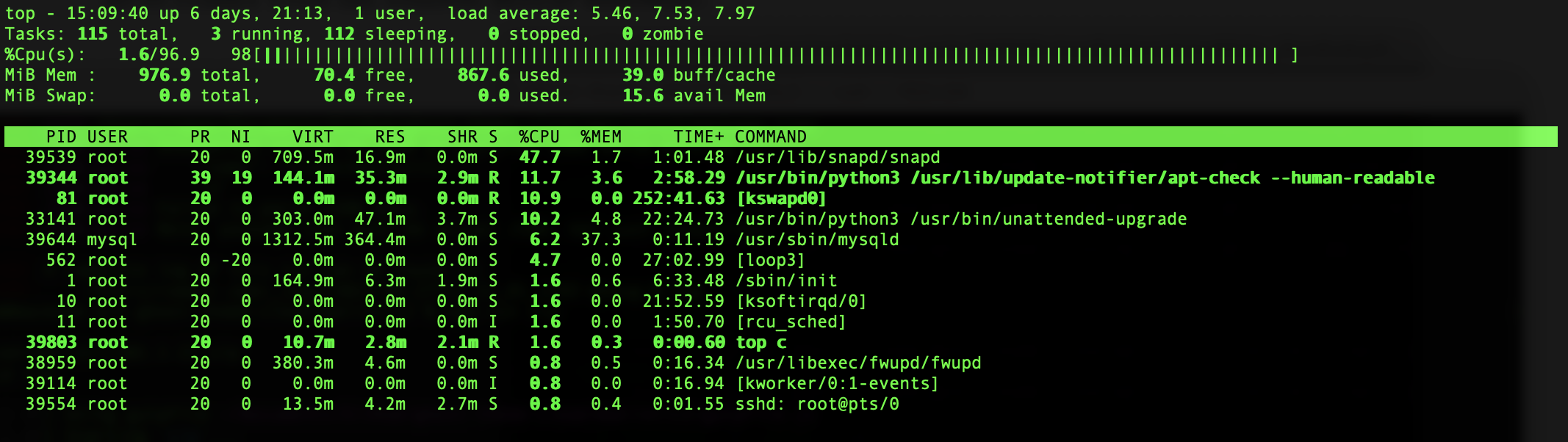
I'm not a Ghost or Linux expert, but after some more back and forth with DO support, we narrowed it down to a problem with how the requirements for running Ghost's matched against the server defaults. I have some thoughts on what was going wrong (see the end notes on caching), but given that most people are more interested in getting their sites back up and prevent them from going down again, I'll jump straight into the solution.
Preventing Periodic Ghost Server Crashes With Memory Swaps
The default answer that most people come across when the Ghost goes down is "just restart your Ghost app with ghost restart!" This is because the problem seems to be an application issue, but if you're already crashing due to 100% CPU utilization, you likely can't even get the Ghost CLI to work to restart Ghost (this was true for me). It's a bit of a catch 22, and reminds me of the folk wisdom: "it's too late to drink a healthy tonic when you're already on your deathbed".
So what can we do to prevent this from happening? Given that the issue seems to stem from high CPU and Memory usage, what worked for me – and countless others – is to manage and diffuse Ghost's CPU and Memory load.
There are two options you can pursue here. I'll use an aviation metaphor to describe them: assume you're trying to land a plane that's lost control. The first option is to build more runway, aka to upgrade your server to a configuration with higher RAM, higher Memory, etc. This will obviously increase your flat monthly costs, but it means your server has more raw space to deal with what you/Ghost throw at it.
The alternative option is to optimize the flight path and performance so that your metaphorical plane doesn't lose control in the first place. This is a no-cost solution that lets your existing configurations work more effectively, and so this is what we'll focus on.
Specifically, you need to build a memory swap on your server. A memory swap guards against out-of-memory errors by allocating hard drive space for temporary memory space when your temporary memory needs outgrow what your RAM can handle. It's not efficient - RAM space is designed differently from SSD (hard drive) space - but it helps with the whole not-bringing-down-the-server problem. And, given that hard drive space is cheaper than RAM (even the lowest Digital Ocean droplet starts with 25gb of hard drive space but only 1gb of RAM), this is a cost effective way for you to solve this problem.
By default, Digital Ocean does not have memory swapping enabled and discourages you from doing so. This is because swaps tend to degrade physical SSD infrastructure over time, and Digital Ocean owns their own hardware. However, this is not in your interest. Digital Ocean recognizes this because they also have a really fantastic and straightforward guide on how to set up and turn on a memory swap. I encourage you to follow that step-by-step guide here.
Once I did that, and both my Memory and CPU dropped to manageable levels, almost immediately. Here's the server analytics again; at roughly 8am, I set up the swap and got the server back online!
Once that was in place, I also set up alerts and more advanced monitoring for my droplet. I hadn't done this on droplet creation, so I had to do this in the console. Luckily, Digital Ocean has another great step by step guide for setting up advanced monitoring and alerting.
Update 1: 14 Days Later
Not only did it solve the immediate problem, this solution persisted. Here's a same view, showing 14 days after implementation:
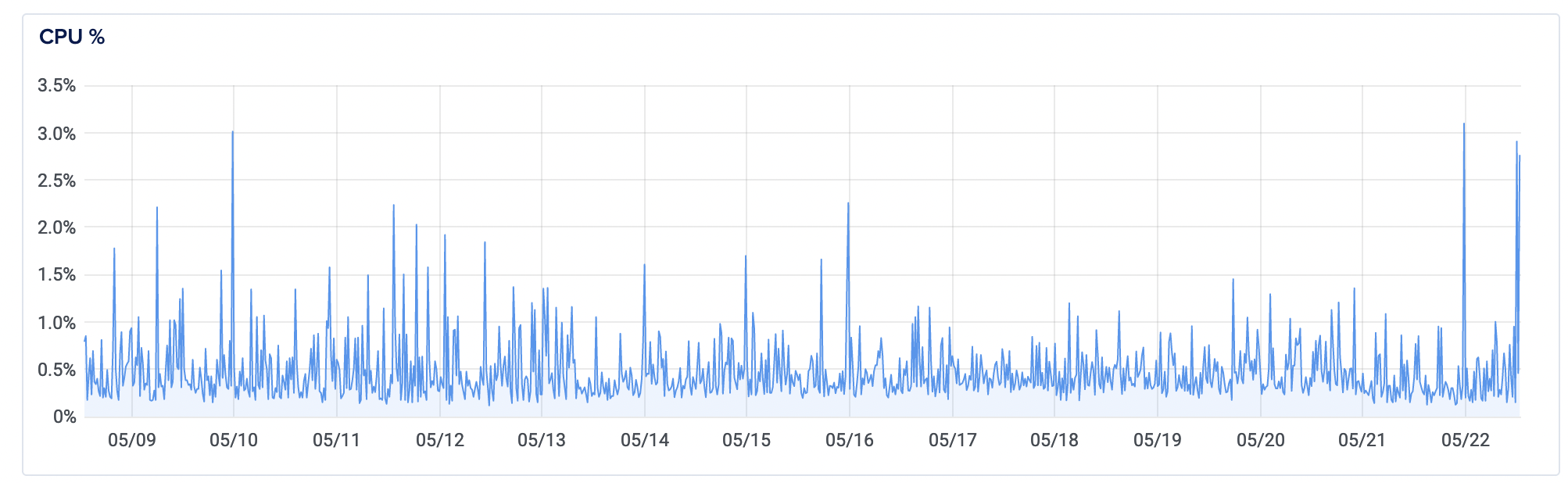
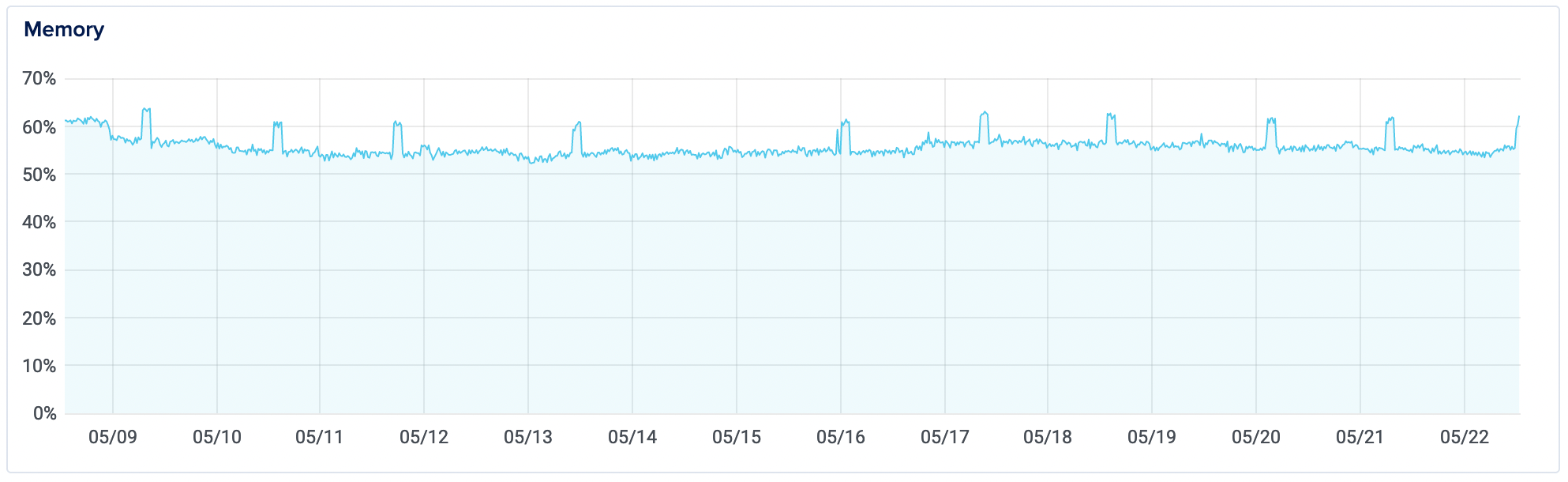
Update 2: Surviving the Hacker News "Hug of Death"
Shortly after implementing this, I published what turned out to be a really popular post on unblocking work in companies: "When Everything Is Important But Nothing Is Getting Done". It ended up on the Hacker New top-10 for a full day and that led to roughly 20k visitors over the next 10 hours, roughly 2k visitors per hour. Google analytics was showing me 80-120 active users on my site for any five-minute span of time during the day.
Not only that, but I quite stupidly misconfigured my newsletter sign-up form and so I started to see a lot of errors being hit on the server as people tried repeatedly to submit information but failed (I only realized this later in the evening).
But how did the memory swap hold up?
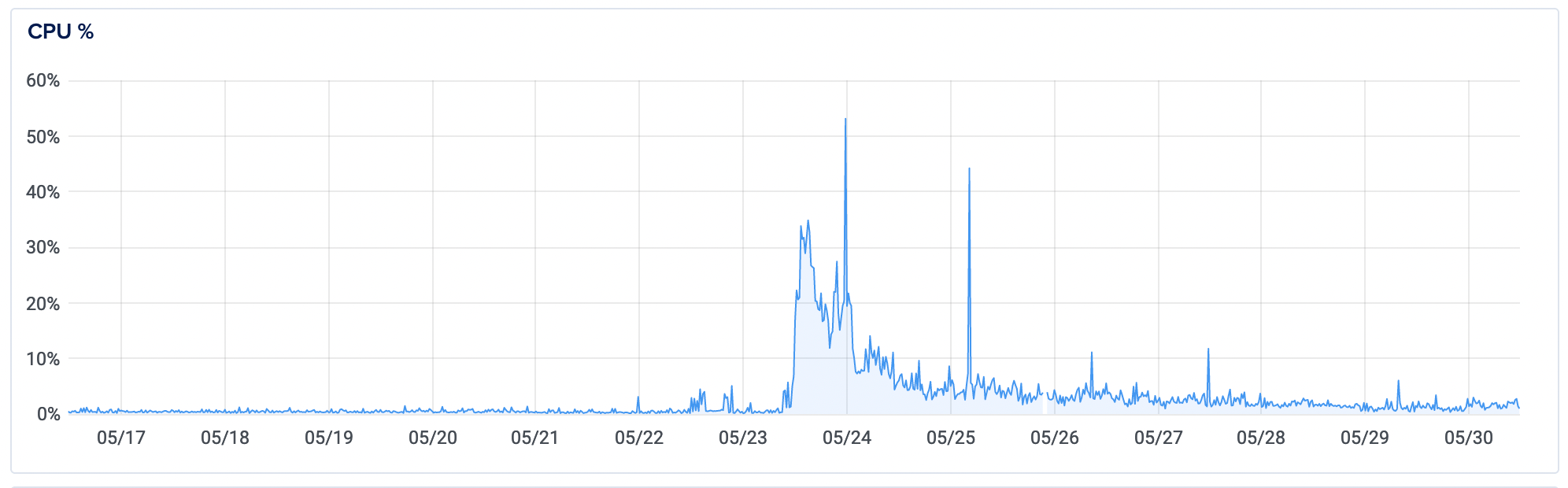
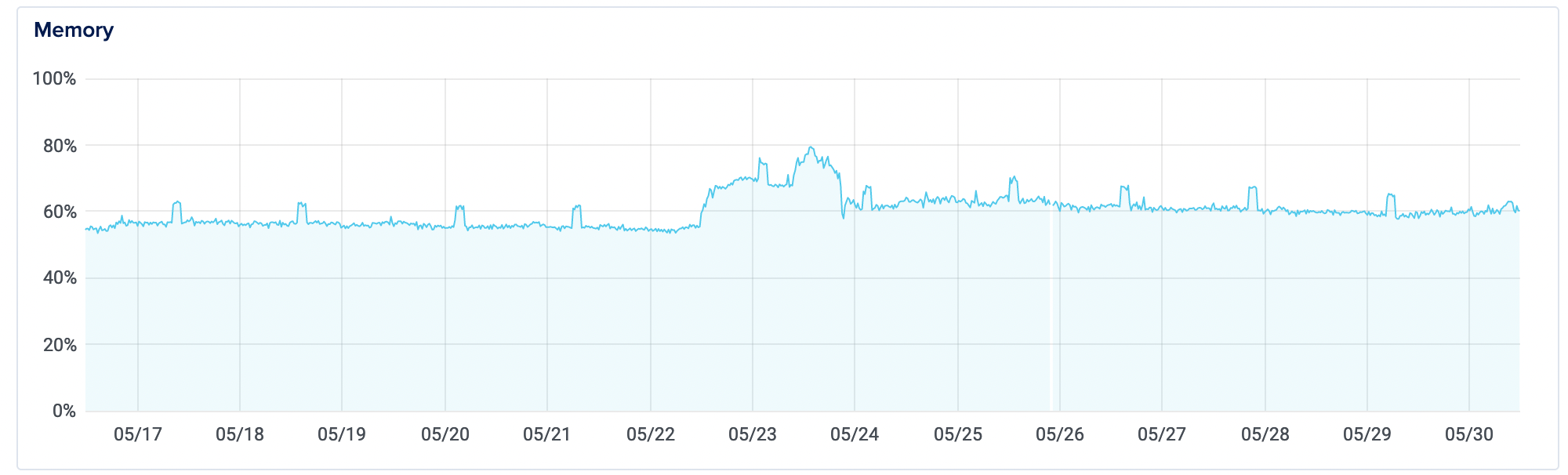
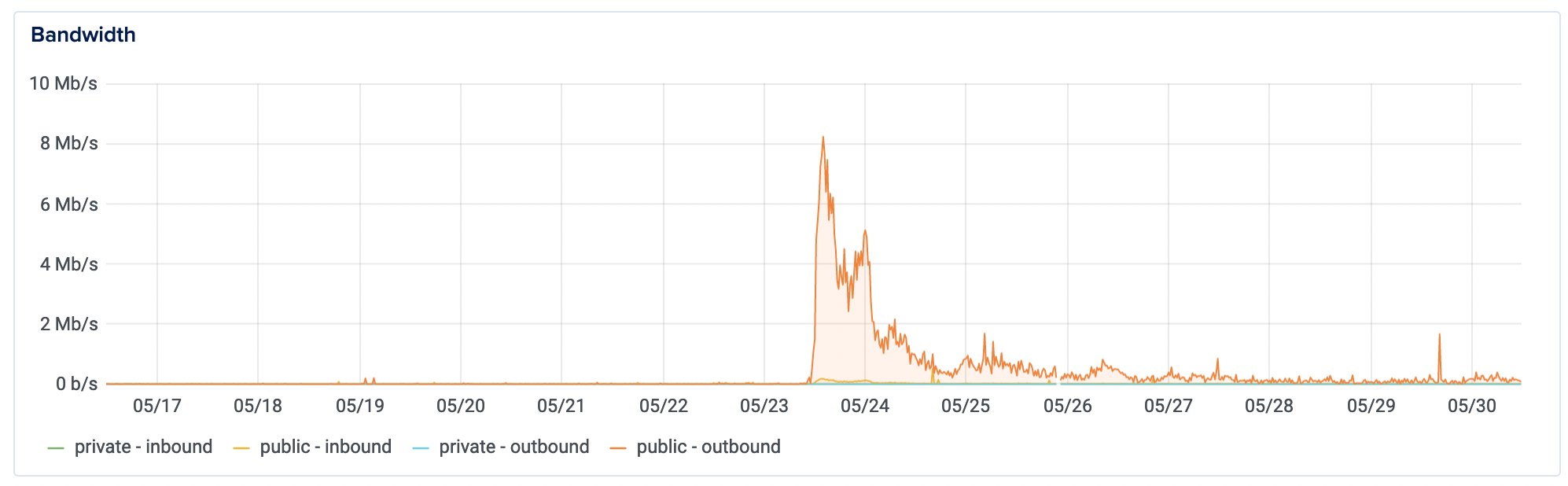
I'm happy to report that the site did not slow down or go down at all during this period. It's not to say that this is a perfect solution (see below; a Cloudflare CDN would have helped even more at this point), but I managed to increase my traffic from 100-per day to 100-per 5 minutes/10000 per day (literally a 10,000% increase in traffic and activity) and the site survived. Cue the party-popper emoji.
The Symptom or the Problem?
Ok! Setting up the memory swap solved for the "my server is crashing!" problem, but it didn't solve for why we were seeing memory and cpu spikes.
My best guess as to why this is happening comes from someone else's explanation of how Ghost works. Ghost is a Node.js application and acts like a hybrid between a static site (such as Hugo or Jekyll, where assets are precompiled and served as a single hard-coded file) and a dynamic site (such as Wordpress, where pages are templates with lots of variables that are compiled when you access them). This means that...
... in development mode, assets will be recompiled upon each request and views will be rerendered. In production mode however, views will be cached. Even with this internal cache, the node.js processes will still have to answer the queries, which doesn’t scale well. [source]
Reading other accounts of similar issues [1][2][3][4][5][6], my best guess is that the actual Ghost/Node.js application is doing something inefficient, most likely on the "querying MySQL" side of things.
This is a useful and believable guess to me because I ran into similar MySQL querying issues when I managed a wordpress ecommerce site at scale (tens of thousands of products/variations and templates). Outside of changing how the core application works to be more efficient, my practical solution was to implement caching, which is...
... storing data temporarily in a high-speed storage layer (for example, in a computer RAM) to serve data faster when clients make the same future requests. This enhances the re-use of previously computed data instead of fetching it each time from the disk. [Source]
When I worked with the ecommerce site, we implemented caching on both the content and application layer. On the application layer, we reduced the work MySQL had to do by using a redis cache in front of it. This helped page load times go down and application efficiency go up. We also placed another cache – Cloudflare CDN cache – in front of the content itself to help further reduce CPU usage and to take advantage of mostly static content that a site holds.
However, setting up the Redis and Cloudflare caches is pretty involved and not something that's very out of the box. This means there's less support for it and a higher risk of failure. If you've read this far, I encourage you to set up memory swaps as it will mostly solve your problem. Past that, I'm going to cover Redis and Cloudflare caching in a part 2 blog post, coming soon.
Stay tuned!
Thanks for reading
Useful? Interesting? Have something to add? Shoot me a note at roman@sharedphysics.com. I love getting email and chatting with readers.
You can also sign up for irregular emails and RSS updates when I post something new.
Who am I?
I'm Roman Kudryashov -- I help healthcare companies solve challenging problems through software development and process design. My longer background is here and I keep track of some of my side projects here.
Stay true,
Roman