Over two weeks, I put Claude 3.7 and ChatGPT 4o through their paces on analyzing real marketing data and creating strategic and tactical artifacts. My goal was to determine if LLMs (Large Language Models) could actually steal my job or just make it easier.
The verdict? LLMs excel at busywork but struggle with nuanced analysis. LLMs swerve toward the generic unless heavily prompted otherwise. They regularly get you to 80% done, but human intervention is required to cross the last 20%. They're powerful copilots for experts but potentially dangerous autopilots for novices. Oh, and templating prompts doesn't seem to have the magical-incantation-for-great-results that some AI influencers suggest... but templates are still great tools for forcing you to organize and prepare information for better input/outputs activity.
Here's what I learned from feeding five years of ad data, eight years of order data, website and marketing copy, and hundreds of customer reviews into these models.
Methodological Details
- Data: Export of five years of Meta advertising data (all available columns, aggregated by week), eight years of order data, four years of customer reviews, export of website copy (homepage, product pages). Personally identifiable data was removed or anonymized as appropriate.
- Prompts: Nine prompt sequences about marketing strategy, five prompt sequences on data analysis, two templating experiments, and notes from various other experiments. I provided limited prompting to not bias the models toward foregone conclusions—I wanted to see what they would come up with, not what I had already concluded. I used identical prompts for both models, with exceptions when one would suggest additional deliverables or require need a nudge to get to a comparable outcome.
- Models tested: Claude 3.7, ChatGPT 4o. Gemini (2.0 and Reasoning) disqualified itself by not being able to ingest .xlsx or .csv data to even get started.
- Caveats: LLMs have a "temperature" setting, which reflects randomness for outputs. This means the same prompt and same starting point can generate different outcomes. This makes controlled experiments and replicable results really hard! So this experiment is not a benchmark – my goal is to convey learnings from real world usage on a limited scope project.
Index:
- Part 1: Advertising Data Analysis
- A Quick Detour: Does Prompt Structure and Templates Design Actually Matter?
- Part 2: Marketing Strategy & Persona Development
- Part 3: Creative Generation
- Part 4: A Meta, Meta-Analysis (Editing This Blog Post)
- Conclusions and Takeaways
Part 1: Advertising Data Analysis
I ran eight years of Meta advertising data through both models for analysis and insight. Here’s what I learned:
Interesting Insights
Both tools created visualizations. Charts and plots are always useful, even for things as simple as “a metric over time”.
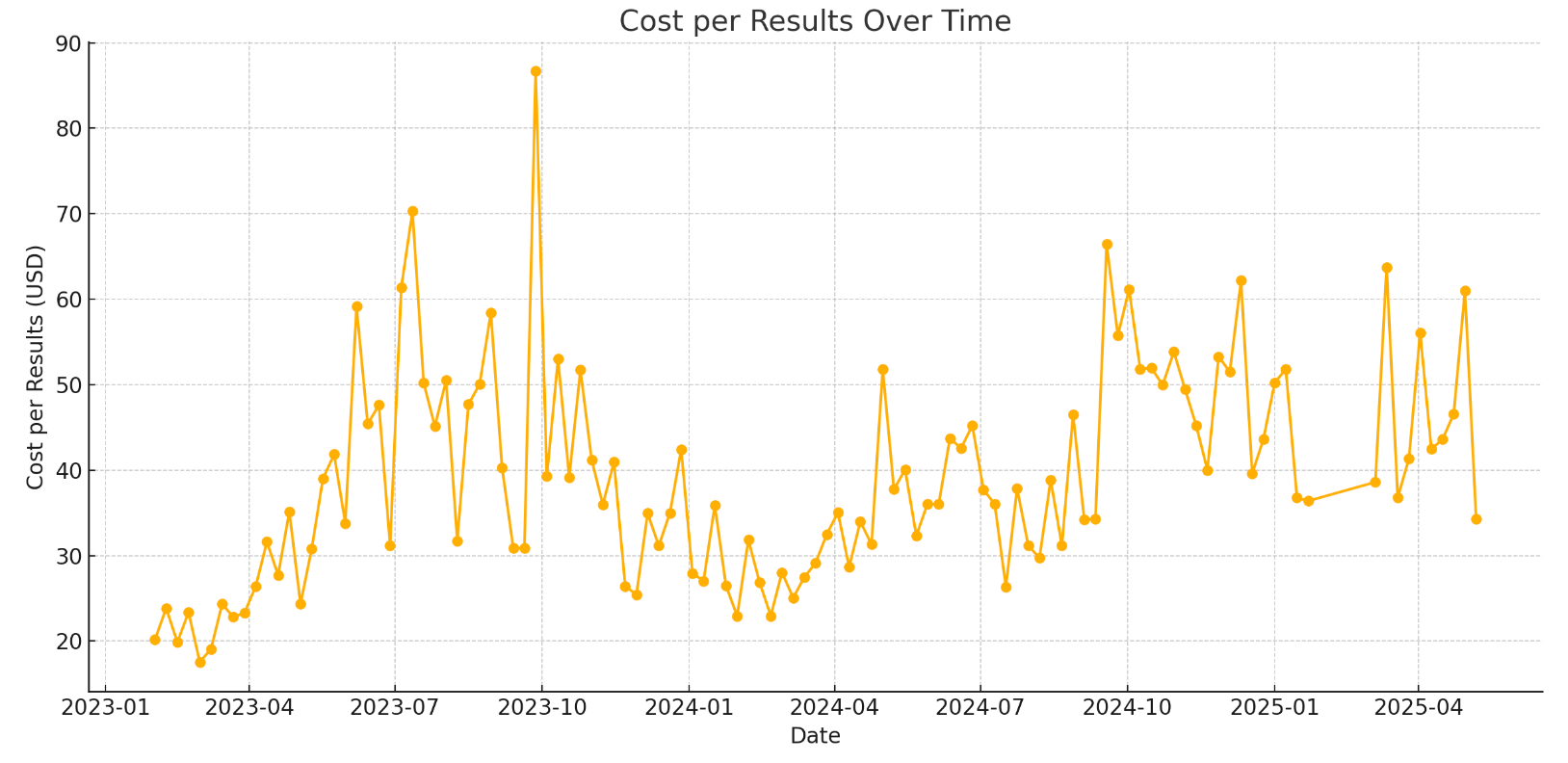
Claude identified seasonality patterns, highlighting recurring performance issues in Q1 and Q2 with increasing severity each year. It discovered this from advertising data alone. My partner and I had guessed at this seasonality, but it was easy to miss in order data alone due to non-advertising marketing efforts during those periods.
Claude further identified audience saturation, creative fatigue, and conversion funnel issues as root causes of recent performance drops. It also suggested investigating competitive landscape changes and algorithm changes outside what could be gleamed from the dataset. Audience saturation and creative fatigue proved correct on independent analysis, but conversion funnel issues were disproven when I checked against my actual website data. The 'change in ads algorithm' assumption was spot-on, correctly pinpointed to Q4 2024.
Most importantly, it highlighted Meta's tracking gaps, which could lead to incorrect conclusions and bad decisions in self-optimizing campaigns.
ChatGPT’s analysis was much more basic, with gems like “The plot shows a clear upward trend in ‘Cost per Results’ recently—confirming that ad performance has worsened (more cost for the same result).” Not quite the level of insight I was looking for! It also highlighted a potential conversion funnel issue… but again, bad data in results in bad conclusions out, and that’s on Meta.
Raw Analysis Limitations
Insight: LLMs struggle with undirected and unprocessed data analysis. They're bad at discovering useful correlations in messy data sets.
Claude and ChatGPT both struggled with undirected analysis and unprocessed data.
Real-world data typically has many direct relationships in its columns. For example, a healthcare data set may include a hospital name, shortcode, and address that can all be described as “structured atomic units of a single datum”. Marketing data has similar interrelationships between columns. This messiness results in superficial LLM gems such as “Campaign name had the strongest correlation with daily spend” or "Results count has the strongest correlation with Cost per results." True, but often not useful.
Separately, the models both began to hallucinate when prompting took the insights back into deliverables. I.e., a prompt around "funnel metrics to monitor" made up columns that did not exist in the data, but looked like it could have.
Model Output Styles
Takeaway: I preferred Claude’s plainer style over ChatGPT's embellishments.
Claude was generally verbose, analytical, plainly written, and provided more interesting insights. It accurately identified plausible algorithm changes and their dates, made reasonable assumptions about performance changes needed, generated better visualizations, and produced more robust analytics code compared to ChatGPT. But that verbosity came at a cost: it frequently hit artifact length limits, requiring reprompting. Longer conversations led to degraded output and occasional interface bugs.
ChatGPT’s outputs showed a preference for emojis and overstyling text (bolding, italics, bullet points, etc.). In short conversations, this was useful. But in longer outputs it felt juvenile, as though someone decorated the output with stickers. ChatGPT also often meta-analyzed a prompt instead of executing it: it would tell me how it would do the work, then ask if I wanted to proceed as described. This pattern appeared more frequently after OpenAI's sycophancy rollback and led to hitting usage limits faster.
ChatGPT also routinely applied a much heavier hand in editing for voice, tone, and content. Any output run through ChatGPT — even with prompting to maintain tone and style — resulted in a variation of the distinct “ChatGPT Voice” that folks complain about. This was especially noticeable when comparing LLM outputs.
Data Gaps and the Principal-Agent Problem
Insight: Any data set is a selective view of the world. Gaps in data lead to poor analysis and inadequate conclusions. Paired with a misalignment between platform and advertiser goals, this can lead to poor optimization.
In reviewing advertising data alone, both LLMs suggested performance dips due to gaps at the point of sale (website funnel and checkout). However, I knew that nothing on the website had changed in 12 months, and website data showed the conversion funnel remained steady. The gap was in the advertising tracking. A self-optimizing campaign at this point would have started to optimize for the wrong (or at least, incomplete) data.
Further prompting and context/data for the LLMs helped to clear this up and come to better conclusions, but autonomous LLM deployments don't have that benefit.
This aligns with a broader concern: Meta and Google's ad optimization incentives are misaligned with user goals. Their interest is in increasing ad spend, with customer outcomes as a corollary, not an end goal. Better performance can lead to less ad spend, and platforms optimize for more spend. (Separately, this is why I regularly opt out of platform-suggested optimizations.)
Claude noticed this pattern in subsequent prompting:
Budget Utilization
- Despite decreasing results, your campaigns are consistently spending the full daily budget
- This indicates Facebook's algorithm is struggling to find efficient conversion opportunities
- The platform is prioritizing spend over performance optimization
Improved Analysis Through Applied Expertise and Supporting Context
Insight: Domain expertise dramatically improves results by enabling better prompting but changes the LLM-User relationship.
Analysis gaps stemmed less from LLM limitations and more from the fundamental garbage-in, garbage-out nature of statistical analysis. The difference between asking "find any correlations" versus specifying a "multi-variable ANOVA-validated analysis with p-value filtering" is enormous. Domain expertise dramatically improves results by facilitating better prompting.
Once the data was cleaned of pseudo-duplicate columns and the LLM was given additional instructions (what to look for and what to ignore), it produced useful insights. Here's an example of such prompting:
"What about a correlation between 'Cost Per Result' with metrics like 'Frequency', 'Adds to Cart', 'Checkouts Initiated'? Nothing on the website or product pricing has changed since these ads started, leading me to believe that recent performance drops are related to something in the advertising performance data. My goal is to identify leading indicators of performance and monitor them when implementing a new ad strategy."
However, this changed the relationship with the LLM. It became less about “can it generate insights for me” (strategic partnership) and more about “can it do some of the typing/grunt work for me” (tactical execution). Still useful, but a different use case.
A Quick Detour: Does Prompt Structure and Templates Design Actually Matter?
If you're a close reader, you might have paused at the section above thinking: "Those are awful prompts! Aren't you using best prompting practices and templates?"
Fair question. I was curious about this too and ran some separate experiments to test if prompt templating significantly impacts output quality.
The Template Experiments
I ran two experiments with ChatGPT:
- Create a children's fable about a fox
- Create a press release for a new product launch
Each experiment had four different prompts:
- A "lazy" prompt (minimal details in a text blob)
- An unstructured but detailed prompt (blob of text, but with more relevant details)
- Two different template variations (for the press release, they were the same 'template' but had different levels of details and color; for the story, they were different templates).
Each prompt was run twice in temporary windows to avoid chat history bias. All four prompts generated similar stories and press releases with interesting unprompted similarities:
- All fox characters had names starting with "F"
- Stories launched in rhyme-sounding woods
- Press releases assumed San Francisco headquarters
- Included quotes from female company representatives
- Featured client quotes from the midwest
Re-runs generated different outputs due to LLM temperature settings creating randomness, and no prompt produced consistently superior results. The prompts and results are available here for review.
My takeaways:
Templates are guides, not magic incantations
Conversations about prompt templates mirror debates about PRDs (Product Requirement Documents)—hundreds of templates exist and everyone seems to have a strong personal preference. But templates serve one purpose: guiding you through organizing information to reach desirable outputs. If you need the structure, use them; if you can organize information effectively without them, skip them.
Frankly, good "prompting" isn't too different from providing good requirements and instructions to a human team. The same principles apply: provide necessary context, details, expected outcomes, and any other critical operational information. In that sense, a great template is – to some degree – a distillation of operational expertise.
Iteration and information matters more than format and structure
Every output needed refinement. Reading outputs revealed obvious directional and informational gaps in the original prompt better than any template. Rather than treating templates as a holy grail, use them as a starting point for iterative development. Information content matters more than information structure, and too much information could be just as bad as too little information.
Production use is different from one-off prompts
There's a crucial distinction between one-off prompting and embedding LLMs in an application. Given output variability, figuring out how to get to reproducibility is critical for productization. Well-defined, multi-layer, iterative, and extensively tested templates are essential for embedded, repeatable use cases and application design.
Bottom line
For the sort of "field deployment" that I'm working on, spending time perfecting (or finding the perfect) prompt templates yields diminishing returns. But I would certainly recommend templates for anyone who is getting started with LLMs as a good way to start thinking about how to effectively engage chat-based interfaces. Templates are also a useful shortcut for figuring out how to deploy an LLM for new use cases and has some merit as a document of creativity and tacit expertise.
Part 2: Marketing Strategy & Persona Development
Both Claude and ChatGPT generated marketing artifacts: strategy guides, personas, advertising content suggestions, positioning, SEO analysis, and landing page rewrites. Both models performed adequately. If a junior marketer had created these outputs, I would have been satisfied enough to move forward.
What Worked Well
- Comparative Performance
Claude and ChatGPT produced similar and complementary outputs. They identified broadly similar personas while suggesting different campaign ideas. Both gave better marketing recommendations than the agencies I'd been speaking with—despite agencies having access to the same data (my website) to work with. - Validation of Intuition
LLM recommendations aligned closely with what my partner and I intuitively knew and had been planning to work on. This occurred even when I reviewed my prompts for potential bias (none found). As an extremely analytical person who doesn't always trust his gut feelings, this was healthy reinforcement that I was on the right track. It helped break me out of analysis paralysis and move forward with implementing ideas I had been on the fence about.
LLMs Excelled in Busywork
The 80% Rule: LLMs excel at synthesis and artifact generation but need human refinement.
LLMs excelled at marketing busywork. For example, I don't know a single person who likes creating personas... and consequently most marketing personas suck and exist only to check boxes. But both ChatGPT and Claude created —for probably the first time in my life—actually useful personas. (Not revolutionary, but very practical for purposes of using them to segment advertising campaigns). This included:
- Technical details for targeting criteria, demographics, and keywords
- Advertising and media ideas
- Real quotes from review data
- Statistical validation of suggestions (e.g., "80 mentions of Dragon Blood Balm for pain management, but only 15 mentions for joint issues")
Synthesizing datasets into usable outputs typically takes me a week of manual work. Having it done in an afternoon of prompting felt revolutionary. But outputs weren't final—I needed another full day of manual review for adjustments and cleanup.
Meta-Analysis Capabilities
After several rounds of prompting, I asked both Claude and ChatGPT to generate documents and guardrails for further prompting. I then ran that document as supplementary data in a prompt to generate a landing page. The results were promising but left me wary of potential content drift over time.
Part 3: Creative Generation
After all that prep work, were the LLMs good at generating media, content, and advertising copy?
Kind of, but not really.
The Generic Trap
Core Problem: LLMs will always swerve toward the generic, the common, and the default unless told otherwise.
Both generated interesting headlines/body copy, but I wouldn't have been comfortable using any without rewrites. For example, one LLM generated: "Plant Power, Not Petroleum”. Snappy, but am I selling clean and renewable energy or a balm for skincare? A rewrite to "Heal with Plants, Not Petroleum" captured the same essence but with more clarity and focus. Or to keep pumping that theme — pun intended — "Jelly should go on your toast, not on your hands", "Petroleum is for engines, not your body". See what I did there? See what the LLM didn't?
Other ads were just slop (and not even AI-level slop). "Harness the Plant Revolution" is a line that could be applied to ... checks ad bank… any wellness-oriented product. Or: "Don’t let pain slow you down". That one's good for... checks ad bank again... any pharmaceutical. That's day 1 intern-level copywriting.
What Makes a Good Ad?
Beyond classic performance metrics, good ads stop your scroll, catch your attention, and encourage engagement. Great advertising goes further—it's a mechanism for discovery, helping articulate feelings and needs people had but may not have expressed yet. They can create interest where none exists. Great advertising balances targeting the right audience with speaking to them effectively.
There’s very little great advertising out there; most people are familiar with bad ads, and bad ads are also thus over-represented in training data. They’re bad because they’re targeting the wrong people (and thus are jarring) or because they’re targeting the right people but are boring or annoying (sometimes offensively so).
Both good and great ads tend to bat left-field. Consider the following ad I ran in 2018:

I don't want to go so far as to say that an LLM can't come up with something like this (or so self-unaware as to pat myself on the back for this as a great ad), but I'm pretty sure an LLM wouldn't come up with something like this without extensive and extremely specific prompting.
Or consider the following:

Again, you could figure out the right prompts to generate something like this, but at that point you fall back into the expert/novice dichotomy in how you’re using LLMs. An expert’s creative direction would get you there but they wouldn’t need the LLM. A novice would get you to slop, and the novice probably wouldn't understand why it’s slop.
I can't emphasize enough that LLMs are statistical best-fit models and so you're always going to get the most probabilistic/common output based on what you put in. Said another way, LLMs will always swerve towards the generic, the common, and the default setting unless told otherwise. And when told otherwise, they will continue to swerve to the version of generic, common, and default that fits your refined prompt.
Content and Landing Pages
Many of the same principles applied to content generation—blog posts, newsletters, and landing pages—with the familiar refrain: garbage in, garbage out.
- Context is everything for content
Prompts lacking context and information produced boring or bogus content. The more detail I provided, the better results I got. My most successful iterations started with loose content outlines and supporting details, then I worked with the LLMs to refine the details and presentation.
ChatGPT outperformed Claude at pulling in additional information, but did not always outperform a web search. The key insight: drafts that started from nothing (e.g., "Draft a blog post about X ingredient") resulted in throwaway work. - LLMs can't replace experience and perspective
Blank-slate drafts resulted in throwaway work because they lacked a certain je ne sais quoi – if all you're doing is generating the most statistically probable content from a prompt, you're going to get the most statistically probable outcome... which in content land, means the equivalent of SEO-farm content. Blog posts that started with a draft outline that I provided were better because they offered a perspective and angle. The best content tended to be LLMs augmenting personal experiences and perspective that I brought to the table with their editing – I brought things that they didn't have, and they provided processing power. - Landing pages were a multimodal challenge
Both LLMs struggled with landing page content, which is inherently multimodal. As any designer knows, describing website layouts with text alone is frustrating—and that's exactly what LLMs force you to do.
While both Claude and ChatGPT could convert descriptions into HTML mockups, the results differed significantly from my actual site. Worse, generating SVG icons or CSS styles consumed significant context window space. The disconnect between textual description and visual execution highlighted a fundamental limitation: LLMs excel at text but struggle with the spatial and visual thinking essential for effective web design.
The pattern held: LLMs are powerful assistants for ideation and initial drafts, but the gap between AI-generated templates and production-ready content remains substantial.
Technical Note: Image Generation
Separately (and this probably goes without saying) — ChatGPT’s image creation overperformed Claude. No comparison here. This meant ChatGPT was more useful for multi-modal content creation. Still, even ChatGPT’s new model wasn’t perfect… Here’s one recent outtake from the post-Ghibli era:

Part 4: A Meta, Meta-Analysis (Editing This Blog Post)
After drafting my initial conclusions, I ran this post that you're reading through both Claude and ChatGPT for editorial review and asked them to rewrite it based on their suggestions.
Voice & Structure
Takeaways: Claude provided light updates, while ChatGPT generated significant rewrites. Use (and compare) both models for the best results.
Claude typically provided minor updates, removing fluff and cleaning typos. It maintained the original voice and structure of my drafts.
ChatGPT provided complete rewrites with extensive tonal changes (even with prompting to not do that), shifting content towards the "ChatGPT voice" in either large or small ways.
To take a random example, consider this section:
My original draft:
Claude and ChatGPT both struggle with undirected and unprocessed data analysis. Specifically, they are bad at discovering useful correlations in messy data sets. Real world data (such as advertising and healthcare data) typically have many columns that have direct relationships with each other. For example, a hospital name, code, and address are all directly related to each other. A clickthrough rate, volume, and metric per 1000 clicks will also typically have strong correlations. This sort of 'dumbness' results in insights such as "Results count has the strongest correlation with Cost per results." True, but not useful.
Claude rewrite:
Claude and ChatGPT both struggle with undirected and unprocessed data analysis. Specifically, they are bad at discovering useful correlations in messy data sets. Real world data (such as advertising and healthcare data) typically have many columns with direct relationships. For example, a hospital name, code, and address are all directly related. A clickthrough rate, volume, and metric per 1000 clicks will also typically have strong correlations. This sort of 'dumbness' results in insights such as "Results count has the strongest correlation with Cost per results." True, but not useful.
Chat GPT rewrite:
Claude and ChatGPT both struggle with messy or undirected data. Real-world marketing data (like ad performance metrics or healthcare data) has many columns with known interrelationships—think "clickthrough rate," "volume," and "cost per 1000 impressions." Yet LLMs often miss the obvious. Example:
"Results count has the strongest correlation with Cost per Result."
Technically true, but completely unhelpful.
My Final Version:
Claude and ChatGPT both struggled with undirected analysis and unprocessed data. Real-world data typically has many direct relationships in its columns. For example, a healthcare data set may include a hospital name, shortcode, and address that can all be described as “structured atomic units of a single datum”. Marketing data has similar interrelationships between columns. This messiness results in superficial LLM gems such as “Campaign name had the strongest correlation with daily spend” or "Results count has the strongest correlation with Cost per results." True, but often not useful.
Differences in Analysis vs. Artifacts on Iteration
Observation: Both models occasionally struggled translating their own analysis into artifacts. Iterative prompting generated output inconsistencies.
ChatGPT and Claude both periodically struggled with translating their own analysis into artifacts (i.e., Prompt 1: "Analyze this text", Prompt 2: "Implement the recommendations"). A close read of both the analysis and subsequent artifacts revealed an occasional lack of continuity between the outputs. Claude had minimal differences, but ChatGPT often went wild with rewrite upon rewrite at each prompt, including regularly changing details, inventing (hallucinating) things, and sometimes changing the intent of a section or providing a different conclusion.
This behavior wasn’t consistent. Sometimes repeat prompting resulted in net improvements over time. Other times, repeated prompting felt like running the same photoshop filter over and over on an image, gradually getting more and more degradation.
That said, I’d still advocate for iterating on an artifact. My go-to prompt was along the lines of, “I rewrote the article and implemented your suggestions. Please go through [analysis details] and suggest changes.” Like collaboration with any editor, subsequent revisions could reveal new potential improvements… or hijack the tone of a work.
All in all, it reinforced the importance of human oversight in the editing process.
Part 5. Conclusions and Takeaways
First and foremost, none of this experimentation would have been possible without 8 years of advertising data, reviews, surveys, and content. Blank-slate experiments produced generic, boring, nearly useless outputs. But what seems "generic and boring" to an expert may be valuable to beginners, so your mileage may vary.
I started out trying to validate how effectively LLMs could process real data and be strategic partners. I was wondering if an LLM could “steal my job” (and hoping it could, because I left marketing as a career tears ago and hate being dragged back).
By the end I was alternatively surprised and disappointed. LLMs are both extremely useful and incomplete. I'm not worried about an LLM replacing me (though a manager may feel otherwise). I had to put in a lot of work to make the LLM pretend to be able to replace, which kind of defeats the point. I would also advise my team not to worry about being replaced by LLMs.
That said, if you’re not putting an LLM in your toolbox (beyond following the crowd to make Ghibli-themed action figures), you’re missing out. But if you’re deploying LLMs uncritically, that's worse. Taking full advantage of an LLM requires strong meta-awareness (thinking about how you think about things), and that's a skill worth exercising whether you're applying it to LLMs or any other work.
1. LLMs Are Statistical Best-Fit Algorithms
Even when an LLM looks like magic (or like emergent properties, for more technically-minded folks), it's helpful to remember that their core is a statistical model for predicting the best next token – kind of like how many web applications are basically data storage and retrieval systems with fancy interfaces. Keeping this in mind makes it easy to notice and avoid certain kinds of LLM-output traps, and to orient yourself for embedding them in applications or using them for one-off projects.
The two biggest applications of this reminder during this field test were that (a) LLMs will always default to the default, and (b) your perspective, expertise, and lived experience are unique things that an LLM can't replicate (but can augment) and that's something worth leaning into. For example: an LLM can create an "explainer post", but it can't create a post that talks about the lived and personal experience of working with the thing that's being explained.
2. LLMs Are Great for Experts, Dangerous for Novices
LLMs excel at ideation, reacting to specific prompting, and artifact generation. But they're unreliable analysts. My review of outputs suggests that it's extremely easy to be misled or to come to incorrect conclusions. Recognizing quality issues, identifying hallucinations, structuring useful prompts, and validating outputs requires at least some basic domain expertise.
With low barriers to use, it’s easy to go wrong without understanding why or where. Users need to bring a bar of competence to compensate for the gaps in LLM capabilities and behaviors.
3. Prompting Matters, But Not Always In Obvious Ways
Input variability, prompt design, and prompt sequencing significantly affect outcomes. But understanding what your inputs include and exclude is equally critical. Any dataset is necessarily a subset of reality and omits critical details. Understanding what's left out is as important as what's included.
Prompt designs can easily bias your outputs (for better and worse). Harking back to expertise, experts can create great prompts but those same experts already have a good idea of what they want. My guess is that as with any tool, experts in a field will use LLMs very differently than beginners and novices.
4. Hallucinations and Accountability
LLMs routinely invent data based on statistical inference from training data. This problem worsens in domains underrepresented in training data. Catching these fabrications requires close attention and cross-checking.
This is why "AI agency" concerns me—tools can't take responsibility for outcomes or be held accountable. "AI agency" obscures critical human responsibility and necessary oversight. Innovations such as Retrieval-Augmented Generation (RAG/Reverse-RAG), Clustering Using Representatives algorithms (CURE), and multiple layers of cross-prompting make significant progress towards output quality, but don't address the ultimate accountability and responsibility questions of when a tool produces bad (or harmful) output.
5. Training Data Is Your Differentiator
My experience suggests custom training data is key for LLM deployment in technical fields. Many companies focus on prompt engineering and basic API integrations. I strongly believe that effective (or innovative) LLM implementation requires, at minimum, custom training datasets or fine-tuning. Augmenting prompts with data is a hack that consumes context windows.
6. The 80% Trap (Copilots, not Agents)
LLMs regularly get you 80-90% of the way to ‘done’. The last 10-20% makes the difference between slop and impact. As output becomes easier and faster, editorial judgment and human refinement become critical skills. Multiple rounds of LLM iteration are helpful, but human synthesis and taste remain essential.
7. If You’re New to AI, You've Got a New Vocabulary
Prompting, artifacts, context windows, training data, tuning layers, temperatures, and different model names are all required learnings for anyone diving into working with LLMs. It is also extremely helpful to understand different kinds of “AIs”, especially the differences between an LLM vs ML (Machine Learning) and NLP (Natural language processing) systems. It’s also helpful to understand where LLMs lead to genuinely emergent behaviors (or emergent-like) and where they behave more similarly to a linear regression model.
8. What This Means for You
- If you're a marketing expert:
You can/should use LLMs for data visualization and reporting, persona creation, and refining first drafts. They're powerful copilots for ideation and busywork but should be closely monitored for quality control. Maybe you don’t need that junior hire you were thinking about. - If you're new to marketing:
Be extremely cautious about trusting LLM outputs without expert review. The confidence of an LLM output masks all the potential ways in which it is wrong. Working outside of an LLMs (books, people) is probably more critical than ever for your development. Lean on LLMs to create fast feedback loops but be wary of their propensity towards positive validation. Work on understanding your environment (company, industry); lean in to developing taste by keeping your eyes open extra wide to everything around you. - If you’re an agency:
LLMs are coming for commodity work. If you’re not augmenting your pitches with LLM analysis, you’re falling behind. Deploy LLMs for the grunt work and specialize in strategy and creative insight.
9. Practical Workflow Recommendations for Marketing LLM Use
- Prepare your data: Clean datasets beforehand, remove pseudo-duplicate columns.
- Structure your prompts: Be specific about analysis methodology and objectives. Provide adequate context. Present some idea of what you’re trying to accomplish.
- Plan your sequence: Use cumulative approaches, building on insights across multiple prompts. If you have chat history on, turn it off if you find a model going off the rails, and start over.
- Cross-validate: Use personal intuition and multiple LLMs for different perspectives. Be critical.
- Plan for refinement: Always allocate time for the critical last 10-20% of human polish.
The future isn't LLMs replacing marketers; it's marketers using LLMs to do more interesting work while leaving the busywork to algorithms.
Thanks for reading
Useful? Interesting? Have something to add? Shoot me a note at roman@sharedphysics.com. I love getting email and chatting with readers.
You can also sign up for irregular emails and RSS updates when I post something new.
Who am I?
I'm Roman Kudryashov -- I help healthcare companies solve challenging problems through software development and process design. My longer background is here and I keep track of some of my side projects here.
Stay true,
Roman